- 概要
- SecurityCon
- Lightning Talk
- Keynote
- Breakouts
- 73,000 Pods a Day, Lessons From Misadventures In Multi-Tenant
- Who Knew Dogfood Could Taste This Good
- Efficient Scheduling Of High Performance Batch
- Lessons Learned From Etcd the Data Inconsistency Issues
- Kubernetes to Cloud Attack Vectors
- What's going ARM
- Remote Control Planes With Konnectivity; What, Why And How?
- The Insider Threat: Third-Party Applications In Your Cluster
- Bare-Metal Chronicles
- まとめ
執筆者 : 岩本 俊弘
概要
KubeCon + CloudNativeCon NA が 2022年10月24日から28日の日程で行われた。 24日と25日には Co-Located Event があり、本体のイベントは25日夕方の Lightning Talks に始まり4日間行われた。
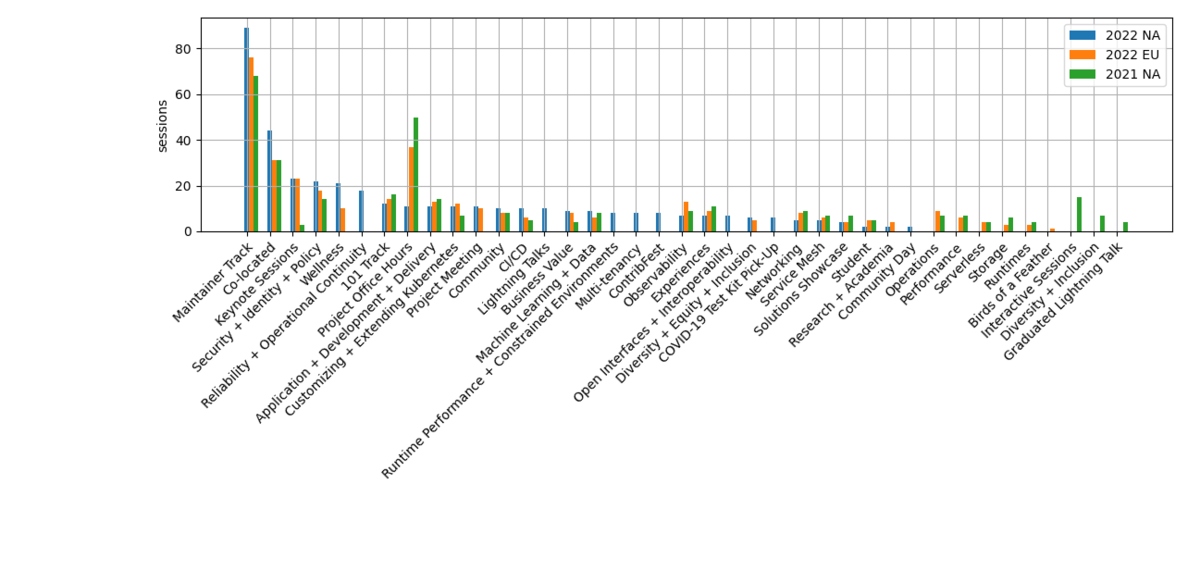
トラック毎のセッション数の比較を下に示す。 Application + Development トラックは今回 Application + Development + Delivery トラックに名称が変わっているが、これらは同じものとして比較している。 今回は新たに multi-tenancy トラックがあった。 ContribFest というのはキーノートでも話があったが、 contributor を増やすための in-person のイベントで、スケジュールでも目立つような表示がされていた。 他にいくつかトラック名の変更や統廃合があったようである。 メンテナトラックは増加傾向にあるが、 CNCF プロジェクト数の増加を反映しているようである。
 全ての発表動画は YouTube の CNCF channel (https://www.youtube.com/c/cloudnativefdn) から参照できる。
全ての発表動画は YouTube の CNCF channel (https://www.youtube.com/c/cloudnativefdn) から参照できる。
今回はデトロイトで開催された。日本との時差が13時間あるので、昼夜がほぼ逆になっており、現地の午後のセッションはあまりチェックできていない。視聴できたセッションのうち個人的に興味深かったものの内容を以下にごく簡単にまとめた。
SecurityCon
今回、Co-Located Event の数は多かったものの、オンラインで同時視聴できたのは SecurityCon, WASM day, eBPF の3つのみであった。 SecurityCon は in-person の参加費が $500 以上するようなものであったため、動画から確認できる限りでは現地での参加者はすごく少なかった。
Securing Access to Kubernetes Infrastructure
k8s apiserver へのアクセスをどうするかという話である。 38万以上の Kubernetes API Server が open になってるといってて心配になる。
bastion とか jump host といった中継サーバに ssh で接続させてそこから apiserver にアクセスさせるというのがよく使われる方法だが、結局その bastion 等が弱点になるなどと説明していた。
必要なユーザに最低限の RBAC を払いだすべきだけど手では管理しきれないとか、 zero trust access はどうあるべきかといった話をしたあと、 paralus (https://paralus.io) の説明になった。
最後に、使ってね(意訳)とまとめていた。
Day in the Life
slim.ai の人による発表である。data scientist だと自己紹介していた。 container security に関して明日レポートを発表するそうで、その内容の説明であった。 レポートは既に公開済みで https://www.slim.ai/blog/container-report-2022 から辿ることができる。
165個のよく使われている public container を anchore とか grype で scan して調べたそうである。 みんなが頑張ってるのに脆弱性の数は増えてて大変だねとか、 メジャーな言語の去年と今年の脆弱性の数を比べたりしていた。おもしろかった。
Detecting Threat in GitHub with Falco
Sysdig の CTO の人による発表である。
GitHub で起きるセキュリティ上の問題として以下のようなものがあると説明していた。
- 秘密をリポジトリに push してしまう
- actions でマイニングを実行されてしまう
- まちがえて private repo を公開してしまう
次に Falco の紹介になって、Falco を GitHub につなぐとか言っていた。 Falco の github plugin (https://github.com/falcosecurity/plugins/tree/master/plugins/github) のことのようである。 変な activity が検出できたとデモしていた。
最後に今晩パーティをやるから来てねと話していて、 virtual 参加の悲しさを感じた。
Pwning the CI
悪意のある pull request を投げることによる攻撃の話である。
PR の title に shell code をいれたりしてデモしていた。 Github Actions workflow で信頼されていないコードがうごくのがまずいと説明していた。
workflow の token の権限についても話していた。 reverse shell がとれたとデモしていた。 self-hosted runner があぶないということのようである。
最後に OpenSSF scorecard (https://github.com/ossf/scorecard) を使って問題を検出しろとか宣伝していた。
Lightning Talk
Securing Envoy: Catching Vulnerabilities With Continuous Fuzz Testing
Envoy で fuzzing でいくつか CVE が見つかったとか、Envoy の fuzzer の書きかたを説明していた。 coverage-guided fuzzer というのを使うと効率的に fuzzing できるそうである。
最後は宣伝っぽくなって、重要な OSS プロジェクトは OSS-Fuzz に応募すると GCP でただで動かせると話していた。
The CNCF Cloud Native Glossary: Trusted. Simple. Community-driven
Glossary というのは用語集のことである。 CNCF のプロジェクトとして整備するということである。 この Glossary は keynote でも紹介されていた。
cloud native terms は多くが vendor のものだから bias があるとか、tech background がないとわからないといった問題を解決するためのものだと意義を説明していて、確かに言葉がわからないとまともな議論を組みたてることはできないので、いいところに目をつけたなと思った。
Keynote
いろんな人が welcome というビデオクリップからスタートした。Hybrid Eventであることを意識か。
CNCF Project Updates も各開発者の動画を映していて、司会が話すよりこっちのほうがいいと思った。 (登壇するプロジェクトもあり)
OSS を使う人が増えたけど contributor は増えていないことに危機感を持っているようで、この状況は unsustainable だと言っていた。 contributor になるためのきっかけを提供するために contribfest というイベントを今回作ったから興味のあるプロジェクトの contribfest に行くように促していた。
Breakouts
73,000 Pods a Day, Lessons From Misadventures In Multi-Tenant
Linux スケジューラと Pod の性能問題のセッションであった。
Pod の requests.cpu では core で指定するけど Linux では時間に変換されて設定されるとか、
CFS では 100ms (period) 毎に CPU の時間が reset されるので 10m core なら 1ms (100ms中) を指定したことになると説明していた。
次に static share とか dynamic share の話になった (burstable で limits を指定しないと cpu.shares のみ設定され cpu.cfs_quota_us は設定されない)。
CFS を 30秒で説明するねとか言ってて楽しそうである。
この場合、 requests.cpu は比だけが問題になる。
結局のところ HPA で Pod の数が scale されて、 1つの Pod で動いてたものが scale して 20 個の Pod で動くようになっても使える CPU の総量は変わらないといった話をしていた。 35% のプロセスが stall して性能が出ないといった問題を抱えていたようである。
次に、CPU utilization は metric として正しいのかという話になって、metric を正しいのにしたら churn がとまったと話していた。
最後に、いままで3回 Reject されたから Feedback よろしくねとかいっていた。 (今回は各セッションの最後に QR コードが映しだされて聴衆が Feedback を入力できるようになっていた。)
Who Knew Dogfood Could Taste This Good
最初に wasm と wasmcloud を説明していた (前回のレポートを参照)。 wasmcloud が提供するフレームワークを自分で使って (dogfooding) wasmcloud を作っているという話である。 event sourcing とか reactive programming とかデザインパターンを話してた。
あまり細かい話はなかった。 これからもこのやりかたを続けて開発していくといっていた。 利益がでるまで何年もかかりそうな感じだが大丈夫かという感想は持ったものの、wasmcloud のフレームワークが実際に使いものになることを身を持って示しているわけで、興味深かった。
Efficient Scheduling Of High Performance Batch
ING (銀行) の話である。 low carbon とか、data-driven company になろうとしてるとか会社の紹介をしていた。
ING で使っている data analytics platform の話である。 hadoop yarn から Kubernetes に変えて Volcano (https://volcano.sh/en/) を使ってるそうである。 オンプレミスのシステムなので、マシンを Kubernetes と Hadoop に分けて構成するのではなく、 Hadoop をつぶして Volcano つかうとマシンの利用効率を改善できるという動機のようである。
Volcano の話は以前も聞いたが、こうやってユーザも増えてるのだなと思った。
Lessons Learned From Etcd the Data Inconsistency Issues
最近の etcd で見つかった data inconsistency バグの話である。
最初に etcd の説明とか、 distributed consensus とか RAFT の話をしていた。 競合を解決する RAFT log の説明もしていた。
メインスピーカーの Benjamin は covid restriction で中国からでられないので録画収録で話していた。 バグは https://github.com/etcd-io/etcd/issues/13766 で、 高負荷でcrashするとcluster内で inconsistent になるというものである。
etcd transaction と BoltDB transaction が別に disk に commit されるのが問題のようである。 昔の設計はよかったけど性能を改善しようと改造したとき壊れたと話していた。 結果としてむだに複雑になったので改造しなきゃよかったのではないかと言っていた。
テストがなかったとか直すのに2週間以上かかったとか問題を分析していて、今後こういうことが起きないように action item を説明していた。
成果として 3.5.5 で data inconsistency check がはいったそうである。 contributor ドキュメントはユーザードキュメントより重要だとか、 contributor 達はプロジェクトに何が重要かについてめったに合意がとれないといった教訓を話していた。
data inconsistency を検出するようなテスト書くの難しいんじゃないという質問もあって、そうだねというか若干ごまかすような回答をしていた。
Kubernetes to Cloud Attack Vectors
managed Kubernetes サービスの話である。 Kubernetes の下のパブリッククラウドの認証トークンが (Podに侵入されたりすることで) 漏れてしまうといろいろ悪いことができるという話である。
認証トークンは不必要に強い権限を持っていて、設定を変更することができるものでも奥深いところまでいかないと設定がかえられなかったりして結構難しいといっていた。
デフォルトはほとんどの場合 secure ではないとか、気付かないところにセキュリテイ問題の原因があるとまとめていて難しいなと思った。
最後は時間切れで、質疑はなかった。
What's going ARM
最初に ARM の説明をして、 Cloud vendor も ARM つくってると話していた。 Airbnb で ARM64 をどう使っているかという話である。
社内の詳しい人を集めて ARM64 に移行するための pilot-team をつくったそうである。 あとは以下のような問題点を話していた。
- OS によって必要な package があったりなかったりする
- package (3rd partyも) build するとかいってる
- CI/CDの設定も multi-arch を考慮してやらないといけない
- build cache が arch-aware じゃなくてはまった
- arch ごとに別の container image 用意してもいいけど universal binary つかう手もある
- arch 名の表記の揺れの吸収 (aarch64 だったり arm64 だったり等)
taints&tolerations で正しい arch で workload が動くようにしてるそうである。 ARM64 のほうがインスタンスの料金が安いといっていたが具体的にいくら節約できたといった話はなかった。
Remote Control Planes With Konnectivity; What, Why And How?
Kubernetes のコントロールプレーンと worker ノードが別のネットワークにある状況の話である。 API -> cluster の connectivity が問題で、 KEP-1281 が 2019 年からあるそうである。
Konnectivity の EgressSelector を設定することで proxy ができて通信できるようになると言っていた。 gRPC で tunnel しているそうである。
konnectivity を含む integration として kubermatic とか k0s があるそうである。 ドキュメントも contributor もないのが問題のようである。
これ大丈夫なのといった風に質問されていたが、 productionでつかってるとのことであった。
The Insider Threat: Third-Party Applications In Your Cluster
第三者のアプリに脆弱性があったらクラスタ全体がやられるという話である。 例として、kiali は ssh key を url で渡すので、dashboard から秘密鍵がとれてしまうとか、 longhorn には認証なしで任意のコマンドが実行できる API があいてたといった話をしていた。
セキュリティを見るにはある一点のリリースじゃなくてプロジェクト全体を見ろとか、 OSSF scorecard が役に立つとか trivy がよくできてると話していた。
常に脆弱性スキャンを監視しろとか、critical な脆弱性は7日以内にパッチあてるようにしろと言っていた。
Bare-Metal Chronicles
冒頭で docker swarm とか mesos とかあったけど最近は Kubernetes だよねとと話していた。 88% が 6個より多いクラスタを運用してる (から運用が大変) とか言っていた。
Cluster API の説明になって、Alibaba とか Tencent の provider もあると言っていたが、本題は tinkerbell provider のようである。
MachineDeployment とか TinkerbellCluster とか CRD の説明をしていた。
gitops で Cluster API を使ってベアメタル上のクラスタを管理するということであった。
まとめ
以上、視聴したセッションのうち興味深かったものを簡単に紹介した。 毎度同じようなことをコメントしている気がするが、出張で他の仕事から切り離されてようやく消化できるような分量があるので、オンライン参加できるのも良し悪しだなと思った。特に今回は時差の関係で見てないものが多くなってしまった。
以前の KubeCon では meetingplay の画面の質疑応答機能を使っていたが、今回は質問は slack channel でやってくれとのことで、質疑応答は会場に参加している人が中心であった。 次回は covid-19 以前に予定されていたアムステルダムで (3年越しで) 開催される。