- 1. vmlinuzの怪
- 2. vmlinuxの入手
- 3. ELFファイル
- 4. ELFセクション
- 5. セクションの意味
- 6. Linuxのセクションとldscript
- 7. .cpuidle.textセクション
- 8. おわりに
執筆者 : 箕浦 真
1. vmlinuzの怪
Linux (カーネル) のファイル名といえば、/boot/vmlinuz-<version>だ。なんでlinux-<version>とかじゃないのだろうか。
vmの方は、これはおそらくBSD Unixのカーネルvmunixに倣ったものだろう。ベル研究所のResearch Unixを、VAXのハードウェアを生かして仮想記憶 (Virtual Memory) 機能を大幅に強化したため、vmunixとした。
zの方は、これは圧縮されていることを表す。なぜZで圧縮なのかはよくわからないが、圧縮の意味なのだ *1。
現在一般的なPCやサーバは、IBM PC/ATという16bit PCから発展してきたものだ (かつてはAT互換機などと呼ばれた)。今でもUEFIではないレガシー環境では起動時は16bit CPU互換のモードで動作している。32bitなり64bitなりのモードに移行するのは、ブートローダかカーネルの役割だ (UEFIではファームウェアが移行する)。16bit CPUで気軽に扱えるサイズに収まらなくなったために、圧縮されるようになったのだと思う。
vmlinuzの本体は伸長プログラムで、データとして圧縮カーネルが埋め込まれている。ブートローダはvmlinuzをストレージ (やネットワーク) から読み込み、vmlinuzのエントリポイントにジャンプする。すると伸長プログラムが動いてLinux本体をメモリに展開、本体にジャンプする、という仕組みだ。
ブートローダをどうにかすればいいじゃん、と思うかもしれないが、そこはLinuxらしく、ブートローダはカーネルとは別プロジェクト (それも複数) で開発されていて、またかつてはブートローダなしで起動する機能もあったりした (本体をddなどでディスクに書き込み、そこから起動する) ので、こういう形になっている。
圧縮前の本体は、Linuxをコンパイルするとできる。kallsyms (バックトレースをログに記録するなどのために、シンボル情報を内蔵している) などの都合で何度もリンクされるが、最終的に「vmlinux」というファイル名でできるはずだ。ここから実行に必要のない部分を削除したりして、arch/x86/boot/compressed/vmlinux.bin.gz (x86の場合) に圧縮され、これをデータとして持つarch/x86/boot/compressed/piggy.o (piggyback: おんぶの意) と、伸長プログラムをリンクした (というか、バイナリレベルで操作してくっつけた) のがbzImageで、これがすなわちvmlinuzである。
vmlinuxは、通常のユーザースペースのCプログラムと同じコンパイラでコンパイルされることもあり、通常のELF形式である *2。
今回は、このvmlinuxで遊んでみたい。
2. vmlinuxの入手
圧縮前のvmlinuxは、別に自分でカーネルをコンパイルするまでもなく、デバッグシンボルと一緒に配布されている。デバッグシンボルは、Red Hat系 (RHEL、Fedora、CentOSなど) ではdebuginfo、Debian系 (Debian、Ubuntuなど) ではdbgsymまたは (拡張子から) ddebと呼ばれるパッケージとして配布されている。CentOS 8では、dnfコマンドでインストールできる *3。
$ dnf repolist --all
repo id repo name status
AppStream CentOS-8 - AppStream enabled
AppStream-source CentOS-8 - AppStream Sources disabled
BaseOS CentOS-8 - Base enabled
BaseOS-source CentOS-8 - BaseOS Sources disabled
Devel CentOS-8 - Devel WARNING! FOR BUILDROOT USE ONLY! disabled
HighAvailability CentOS-8 - HA disabled
PowerTools CentOS-8 - PowerTools disabled
base-debuginfo CentOS-8 - Debuginfo disabled
c8-media-AppStream CentOS-AppStream-8 - Media disabled
c8-media-BaseOS CentOS-BaseOS-8 - Media disabled
centosplus CentOS-8 - Plus disabled
centosplus-source CentOS-8 - Plus Sources disabled
cr CentOS-8 - cr disabled
extras CentOS-8 - Extras enabled
extras-source CentOS-8 - Extras Sources disabled
fasttrack CentOS-8 - fasttrack disabled
$ sudo dnf --enablerepo=base-debuginfo debuginfo-install kernel
[略]
Dependencies resolved.
================================================================================
Package Arch Version Repository Size
================================================================================
Installing:
kernel-debuginfo x86_64 4.18.0-193.14.2.el8_2 base-debuginfo 497 M
Installing dependencies:
kernel-debuginfo-common-x86_64
x86_64 4.18.0-193.14.2.el8_2 base-debuginfo 57 M
Transaction Summary
================================================================================
Install 2 Packages
Total download size: 554 M
Installed size: 2.9 G
Is this ok [y/N]:
Debian系ではapt lineを編集し、aptコマンドで (通常のパッケージと同じように) インストールする。ここでは手順は割愛する (Ubuntuの例)。以下の実行例は、CentOS 8.2.2004のものである。更新の適用状況でハッシュ値などが異なる可能性があるのはご容赦いただきたい。
カーネルのデバッグシンボルには、各モジュールのデバッグシンボルの他にvmlinuxが入っている。Red Hat系では/usr/lib/debug/lib/modules/<version>/vmlinuxに、Debian系では/usr/lib/debug/boot/vmlinux-<version>に、それぞれインストールされている。
$ file /usr/lib/debug/lib/modules/`uname -r`/vmlinux /usr/lib/debug/lib/modules/4.18.0-193.14.2.el8_2.x86_64/vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, BuildID[sha1]=05f1c05695a786aad2fc246ce4ef75a12e5c685e, with debug_info, not stripped $ file /bin/cat /bin/cat: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=007217a03b8c26e9ea643d55aa19c19b120143b4, stripped
通常のコマンドとは異なり、スタティックリンクである。またデバッグシンボルパッケージに含まれていることもあり、デバッグ情報やシンボル情報が削除されていない (not stripped) のも分かる。
3. ELFファイル
vmlinuxもELFファイルなので、通常のobjdumpなどで情報が見られる。またELFに特化したプログラムとして、readelf (binutilsの他、elfutilsパッケージに実装の異なるものが含まれる) も利用できる。これらのプログラムを使って、vmlinuxを観察してみよう。
ELFファイルは、ファイルヘッダ (ELFヘッダ) に続いて (プログラムとしてロードした時の動きを記した) プログラムヘッダ、その後に複数のセクションが続くという構成になっている。各セクションには、セクションヘッダが付く。3種類のヘッダにはメタデータ的な情報のみが記録されているため、実際のコードやデータは各セクションに分割されて格納されることがわかる。
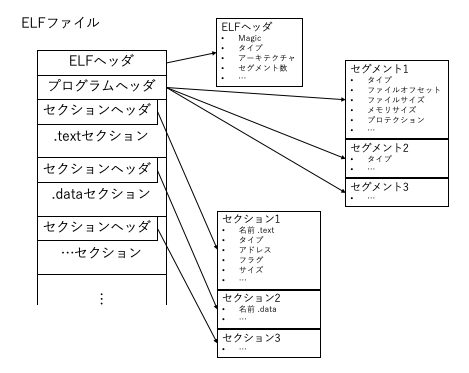
ELFヘッダとプログラムヘッダは、それぞれreadelfの-h、-lオプションで表示できる (-Wはwide表示)。
$ readelf -Whl /usr/lib/debug/lib/modules/`uname -r`/vmlinux ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x1000000 Start of program headers: 64 (bytes into file) Start of section headers: 764236888 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 5 Size of section headers: 64 (bytes) Number of section headers: 81 Section header string table index: 80 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align LOAD 0x200000 0xffffffff81000000 0x0000000001000000 0x11c2000 0x11c2000 R E 0x200000 LOAD 0x1400000 0xffffffff82200000 0x0000000002200000 0x74b000 0x74b000 RW 0x200000 LOAD 0x1c00000 0x0000000000000000 0x000000000294b000 0x02c000 0x02c000 RW 0x200000 LOAD 0x1d77000 0xffffffff82977000 0x0000000002977000 0xe89000 0xe89000 RWE 0x200000 NOTE 0xe013f4 0xffffffff81c013f4 0x0000000001c013f4 0x0001a4 0x0001a4 0x4 Section to Segment mapping: Segment Sections... 00 .text .notes __ex_table .rodata .pci_fixup __ksymtab __ksymtab_gpl __kcrctab __kcrctab_gpl __ksymtab_strings __param __modver 01 .data .BTF __bug_table .orc_unwind_ip .orc_unwind .orc_lookup .vvar 02 .data..percpu 03 .init.text .altinstr_aux .init.data .x86_cpu_dev.init .parainstructions .altinstructions .altinstr_replacement .iommu_table .apicdrivers .exit.text .smp_locks .data_nosave .bss .brk .init.scratch 04 .notes
ELFヘッダの情報は、なんとなく分かるのではないだろうか。余談だが、ELF (Executable and Linkable Format) は、実行ファイルのほか共有ライブラリ (拡張子.so)、リンク前のオブジェクトファイル (拡張子.o)、ユーザースペースプログラムが異常終了した時のcoreファイルなどでも使われており、ELFヘッダのType:で種類が示される。
プログラムヘッダを見ると、5つのメモリセグメントに分かれていることが記されている。たとえば先頭行に対応するセグメントには、ファイルオフセット0x2000000以降に書かれている内容が読み込まれ、そのサイズは0x11c2000バイト (ファイル上もメモリ上も同じ) で、プロテクション (メモリのrwxパーミッションに相当する) は読み出し (R) と実行 (E) のみが許可される。PhysAddrは、カーネルやROMの中身など特殊な例で活用され (通常のプログラムではVirtAddrと同じ)、名の通り物理アドレスを表す。このように、プログラムヘッダは、セグメントの情報をセグメント数だけ並べた構造になっている。
ファイルオフセット (第2項「Offset」) と各セクションヘッダから算出された、各セクションとの対応がその下「Section to Segment mapping」に表示されている。これは、Program Headersの1行目のエントリ (Offset 0x200000) に対応するセグメント (00) に、.text、.notes、__ex_table、… というセクションが対応し、読み込まれることを示す。
伝統的にはUnixのプロセスは、text、data、bssの3つのセグメントからなる。textは機械語コード、dataは初期値あり大域変数、bssは初期値なし (0フィル) 大域変数を示し、実行時にはこの他にスタックやヒープが確保される。現在ではダイナミックリンク用、デバッグ用などで、セグメントの種類が膨れあがっており、readelf -lW /bin/catとすると、10のセグメントが表示される。vmlinuxのセグメント数はこれよりは少ない。
4. ELFセクション
ではELFセクションとはなんだろうか。表示形式から見ても分かるように、セグメントとセクションは1対多対応の関係にある。vmlinuxのSection to Segment mappingを見ると、.notesセクションがセグメント00と04の2度登場しているのも確認できる。
実は、GNU Assemblerには、コードやデータを特定のセクションに置くよう指示するディレクティブ (機械語命令と対応しない、アセンブラ自身への指示) がある。たとえば、以下のようなCソースコードをgccでコンパイルしてみる。
$ cat hello.c
#include <stdio.h>
int var1 = 100;
int
main(void)
{
printf("Hello, world!\n");
return 0;
}
$ gcc -S -o - hello.c
.file "hello.c"
.text
.globl var1
.data
.align 4
.type var1, @object
.size var1, 4
var1:
.long 100
.section .rodata
.LC0:
.string "Hello, world!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
call puts
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 8.3.1 20191121 (Red Hat 8.3.1-5)"
.section .note.GNU-stack,"",@progbits
.で始まるのがアセンブラディレクティブだ。var1というシンボルは、.dataというディレクティブの少し下にあるが、.dataディレクティブがこの先を.dataセクションに置くことを指定するものだ。同様に、mainというシンボルは、.textディレクティブの下にあり、.textセクションに置かれる。.text、.dataのほか、.bssというディレクティブがあり、.bssは.bssセクションを指定する。
任意のセクションに配置するには、.sectionディレクティブを使う。.section .rodataというディレクティブが見えるが、これによりHello, world!という文字列が.rodataセクションに置かれる。read only dataの意味だ。
Cのプログラムでは、.sectionなどをasm()の中に書けば良いのだが、実はgccの拡張機能で関数や大域変数を任意のセクションに置くことができる。
5. セクションの意味
セクションの効果は何だろうか。先ほどのreadelfの結果にあるように、ELFセクションを変えると異なるセグメントに読み込むことができる。通常.textセクションの部分は、textセグメントに読み込まれるし、.dataセクションの部分はdataセグメントに読み込まれる。
また、複数のソースファイルから作られるプログラムでも、同一セクションの関数や変数はリンク時に1箇所にかき集めてリンクされる。.textセクション、.dataセクションを考えれば自然だろう。順番通りにリンクされると、textセグメント、dataセグメント (プロテクションが異なる) が交互に現れることになってしまう。以下の例をコンパイルしてみると、
$ cat h.h
#ifdef NO_SECTION_ATTRS
#define text1
#define text2
#else
#define text1 __attribute__((section(".text1")))
#define text2 __attribute__((section(".text2")))
#endif
extern int f1(int) text1;
extern int f2(int) text2;
extern int g1(int) text1;
extern int g2(int) text2;
$ cat f.c
#include <stdio.h>
#include <stdlib.h>
#include "h.h"
int arg = 10; /* in the data section */
int
main(int argc, char *argv[])
{
if (argc == 2)
arg = atoi(argv[1]);
else if (argc != 1)
exit(EXIT_FAILURE);
printf("result: %d\n", f1(arg));
return 0;
}
int f1(int i)
{
return g1(i) + 10;
}
int f2(int i)
{
return g2(i) + 10;
}
$ cat g.c
#include "h.h"
int g1(int i)
{
return f2(i) + 10;
}
int g2(int i)
{
return i + 10;
}
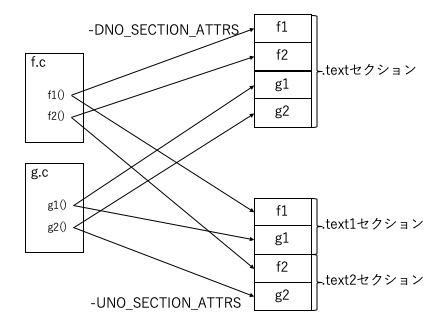
-DNO_SECTION_ATTRSを付けてコンパイルすると、section属性がつかないので、f1、f2、g1、g2は全て定義順にtextセクションに集められる。
$ gcc f.c g.c -DNO_SECTION_ATTRS $ objdump -t a.out | sort | grep '[fg][12]' 000000000040067b g F .text 000000000000001a f1 0000000000400695 g F .text 000000000000001a f2 00000000004006af g F .text 000000000000001a g1 00000000004006c9 g F .text 000000000000000f g2
NO_SECTION_ATTRSを定義しないでコンパイルすると、section属性がつくので、f1とg1、f2とg2がそれぞれ集められる。
$ gcc f.c g.c -UNO_SECTION_ATTRS $ objdump -t a.out | sort | grep '[fg][12]' 00000000004006f5 g F .text1 000000000000001a f1 000000000040070f g F .text1 000000000000001a g1 0000000000400729 g F .text2 000000000000001a f2 0000000000400743 g F .text2 000000000000000f g2
6. Linuxのセクションとldscript
Linuxのソースコードを見ると、実に多くのセクションが定義されていることがわかる。たとえば、__cpuidleというキーワードをつけた関数は、.cpuidle.textというセクションに配置される。
/* Attach to any functions which should be considered cpuidle. */
#define __cpuidle __attribute__((__section__(".cpuidle.text")))
こんな感じだ。
/*
* We use this if we don't have any better idle routine..
*/
void __cpuidle default_idle(void)
{
trace_cpu_idle_rcuidle(1, smp_processor_id());
safe_halt();
trace_cpu_idle_rcuidle(PWR_EVENT_EXIT, smp_processor_id());
}
と、ここで、先ほど引用したvmlinuxのセグメントヘッダを思い出してみよう。せっかくなのでセクションヘッダを出力する-Sオプションも使ってみると、
$ readelf -Whl /usr/lib/debug/lib/modules/`uname -r`/vmlinux | grep cpuidle $ readelf -WS /usr/lib/debug/lib/modules/`uname -r`/vmlinux | grep cpuidle
そんなセクションはない! これはどういうことだろう。
実は、.text.cpuidleセクションは、Linuxコンパイル中にできる*.oファイルの中には存在するが、vmlinuxからは意図的に消されるのだ。GNU ldには、複数のセクションをまとめて1つのセクションに出力する機能があり、ldscriptというものを書くことでそれができるようになる。
vmlinuxのldscriptは、arch/x86/kernel/vmlinux.lds.Sにある。一見Cで書かれているように見えるが、これはCのプリプロセッサの機能を使っているためである。プリプロセッサを通った後のldscriptは、コンパイル途中のarch/x86/kernel/vmlinux.ldsに作られるが、見づらいのでプリプロセス前のファイルを参照するのが良さそうだ。
セクションの定義は、SECTIONS{}という中にあるが、先にセグメントの定義を見ておこう。Cプリプロセッサの#ifは展開してある。
PHDRS {
text PT_LOAD FLAGS(5);
data PT_LOAD FLAGS(6);
percpu PT_LOAD FLAGS(6);
init PT_LOAD FLAGS(7);
note PT_NOTE FLAGS(0);
}
先に見た通り、セグメントはプログラムヘッダで定義されているので、PHDRS{}というところで定義されている。textやdataがセグメント名、PT_LOADというのはreadelf -lのType項のLOADに対応する。他にPT_NOTE (コードでもデータでもない情報) やPT_DYNAMIC (ダイナミックリンク関連) などがある。FLAGSは、同じくFlg項で、プロテクションを表す。chmodの8進数と同様で、textセグメントはrx、dataセグメントはrw、initセグメントはrwxだとわかる。
vmlinuxのセクションの定義は複雑なので、まずは書式を簡単に説明しておこう。単純な例だとこんな感じだ。
SECTION {
.text: { *(.text) } :text
/* 略 */
}
textが3つもあってとてもわかりにくいが、最初の.textは、出力ファイルのセクションを表す。2つめの *(.text) の * は、入力ファイル (お馴染みワイルドカードで全てのファイル) を表し、.textがそのファイルの.textセクションを表す。最後のtextは、PHDRSで定義したtextセグメントである。まとめると、全ての入力ファイルの.textセクションを、出力ファイルでは.textセクションにあつめ、textセグメントにロードする、という意味になる。
他に、GNU ldでシンボルを定義することもできる。たとえば、
SECTION {
.text: {
_text = .;
*(.text)
_etext = .;
} :text
/* 略 */
}
.は、現在のロケーションカウンタ、と定義されていて、上の例だと.textセクションの先頭が_text、末尾が_etextに入る。このシンボルは、Cソースからもextern void *_text;のように参照することができる。.textセクションの位置やサイズは、全てのファイルをリンクしてみないと分からないので、これらの値を決められるのはldだけ、というわけだ。
7. .cpuidle.textセクション
以上を踏まえて、vmlinuxのセクション定義を見てみよう。.cpuidle.textセクションを例にしてみる。
.textセクションの中に、CPUIDLE_TEXTというのがあるが、これは#includeされているinclude/asm-generic/vmlinux.lds.hのなかで定義されている。
#define CPUIDLE_TEXT \
ALIGN_FUNCTION(); \
__cpuidle_text_start = .; \
*(.cpuidle.text) \
__cpuidle_text_end = .;
ALIGN_FUNCTION()は、上の方で定義されている通り8バイトアラインを指定している。全ての入力ファイルの.cpuidle.textセクションを集めてここにリンクせよ、という指示で、先頭に__cpuidle_text_start、末尾に__cpuidle_text_endというシンボルをそれぞれ付与している。このシンボルは、この辺りで宣言されており、実際にその下で参照されている。
bool cpu_in_idle(unsigned long pc)
{
return pc >= (unsigned long)__cpuidle_text_start &&
pc < (unsigned long)__cpuidle_text_end;
}
引数としてプログラムカウンタを取り、.cpuidle.textセクションの中のアドレスであれば真を返す。つまり、__cpuidleの関数を実行中であれば、アイドル状態であると判断できるわけだ。
もっとも、実際にこのコードを使っているのは、デバッグ/トラブルシューティング用途の部分のみのようだ。
なお、具体的に、cpu_in_idle()が真を返すアドレスに含まれるシンボル群は、vmlinuxを見なくても、/boot/System.map-<version>で「__cpuidle_text_start」「__cpuidle_text_end」をキーに検索するとわかる。
$ sudo sed -ne /__cpuidle_text_start/,/__cpuidle_text_end/p /boot/System.map-`uname -r` ffffffff81894400 T __cpuidle_text_start ffffffff81894400 T default_idle ffffffff81894530 t mwait_idle ffffffff818946f0 T acpi_processor_ffh_cstate_enter ffffffff818947a0 t native_safe_halt ffffffff818947b0 t native_halt ffffffff818947c0 t cpu_idle_poll ffffffff81894930 T default_idle_call ffffffff81894960 t intel_idle ffffffff81894a90 t acpi_safe_halt ffffffff81894ac0 t acpi_idle_do_entry ffffffff81894af0 t poll_idle ffffffff81894ba6 T __cpuidle_text_end
他に、.spinlock.textとか、.sched.textのセクションも、似たような目的で使われているので興味のある方は調べてみてほしい。
8. おわりに
本当は別な内容を書くつもりで導入部として書き始めたのがずいぶん長くなってしまった。次回は他のセクションを見てみたいところ。