- 概要
- Cloud Native Wasm Day
- Cloud Native SecurityCon Europe day 2
- KubeCon
- まとめ
執筆者 : 岩本 俊弘
概要
KubeCon + CloudNativeCon EU が 2022年5月16日から20日の日程で行われた。 16日と17日には co-located event があり、本体のイベントは18日からの3日間であった。
トラック毎のセッション数の比較を下に示す。 増減がはっきりしないものがほとんどであるが、"Security + Identity + Policy" と Observability と "Customizing + Extending kubernetes" は増えているように見える。
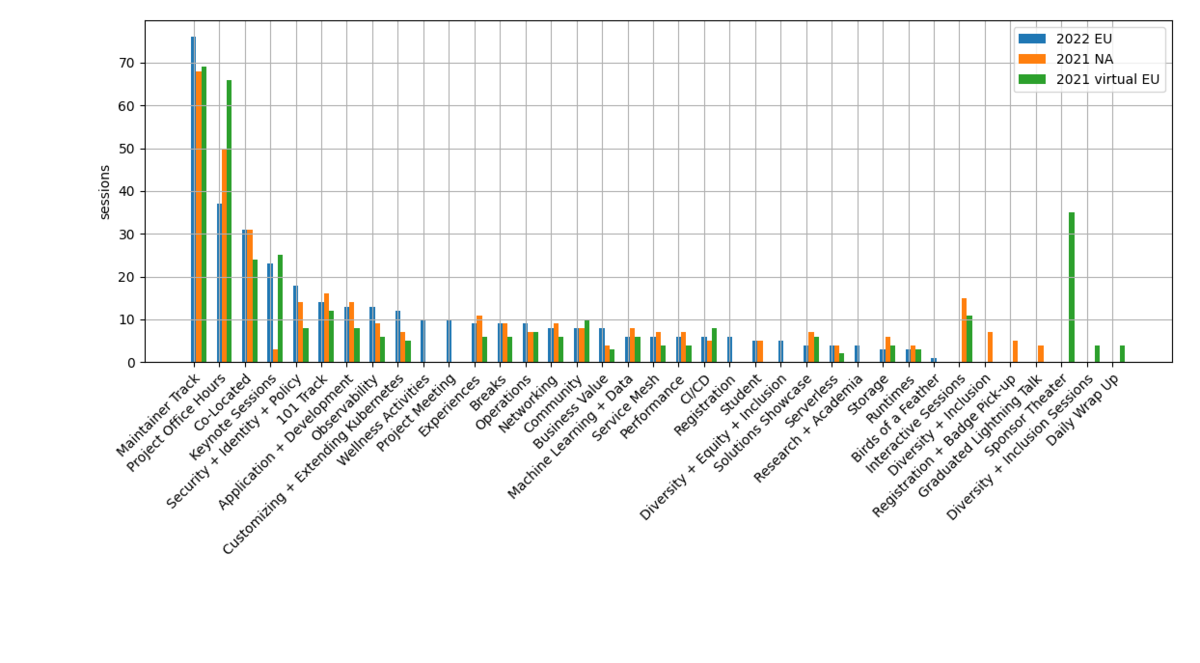
前回に引き続き、会場とネット配信のハイブリッド開催で、co-located event では配信のトラブルがいくつかあったが、KubeCon 本体ではほぼ問題なく視聴できた。
全ての発表動画は YouTube の CNCF channel (https://www.youtube.com/c/cloudnativefdn) から参照できる。
Cloud Native Wasm Day
1日目は WebAssembly (Wasm) のイベントを視聴した。Wasm にすることで (CPUの違いや、サーバやクライアント側といった違いのある) 様々な環境で動かすことができるといったメリットがある。 セッションではそういったメリットを生かした応用例が多く話されていたが、エコシステムを広げて Wasm を流行らせたいといった雰囲気を感じるものもいくつかあった。
Keynote: View from Above: A Birds-eye View of the Wasm Landscape and Where It's Heading
2012年頃の昔話から始まった。200万行の C++ で書いたものを色んな環境とか web で動かしたくて、asm.js とかいうものを作ってやろうとしたけど上手くいかなかったとのことである。
2015年になって Wasm ができて、その昔やろうとしていたことができるようになって、また、Wasm にすることで実行環境の違いの考慮も楽になると話していた。
他に、WASI、ランタイム、Wasm で使える言語の話など一通りの話をしていた。 Python 等も Wasm 上で使えるという話もしていて、これについては後のセッションで詳しい話がでてきた。
Wasm は Cloud Native だとも言っていた。 Container より速く起動して memory footprint も小さいからだそうで、Cloud 環境で Wasm を動かすようにすればコストも下げられるのではと言っていた。
将来の話として、Wasm がデフォルトのコンパイルターゲットになるといいなとか、アプリがプラグインみたいになって開発者が例えば http handler だけ開発して他はインフラが面倒をみるようになる (といいな) などと話していた。
このキーノートは Wasm の現状を説明するよいまとめになっていた。
What If... Kubernetes Core Pieces Could Be Extended with Pluggable WebAssembly Modules?
Wasm をプラグインとして使うという話である。最初に kubewarden の話をしている (去年のレポートにもあり)。 admission controller を Wasm で書けるというもので、webhook は Network を経由するから uncertainty があるし attack surface が増えるのでよくないといってる。更にWasmの方がリソースの消費も少ないと主張していた。
kubewarden のデモをした後、他になにか Wasm を使えないかという話をしていた。 データプレーンの拡張としては envoy で使えるそうである。 ユーザーランドの拡張として krew-wasm の話になった。kubectl のプラグインが Wasm で書けるというものである。
最後に WASI の話をしていた。プラグインからホストの設定ファイルを参照したり、複雑なことをするときにホスト上で処理をしたりといったときに便利だということを言っていた。
WASI networking
WASI は WebAssembly System Interface の略である。 ファイルの操作等を行うには Wasm バイトコードとその下の native code をつなぐ interface が必要になるが、勝手にやっちゃうと移植性がなくなるから WASI で標準化しているのだとの簡単な説明をしていた。
WASI の歴史を説明していた。2020年に snapshot 1 が出て、さらに最近は、各実装が必要な interface を選んで実装できるようにするためにモジュール化されているとのことである。
snapshot 1 では sock_accept が定義されたが、まだ新しい listener を作ったり外向きの接続をしたりといった機能はないそうである。wasi-sockets (https://github.com/WebAssembly/wasi-sockets/) を提案していると言っていた。
後半なぜか confidential computing の話になった。 enarx (https://enarx.dev/) で TLS を使っているとかで、さっきの WASI networking の話と関係あるようだがよくわからない。 デモをしながら、暗号化されてるから Wasm のメモリの中がみえるかどうかとか、attestation がどうとか言っていた。
単に socket API を作るわけにはいかなくて、セキュリティを考えて設計しないといけないから大変なんだなと思った。
Lightning Talk: From Hardware Simulation to Real Devices with WebAssembly Using TinyGo
いろんな名前で呼ばれるけど @deadprogram だと自己紹介していた。
最初は tinygo の話で、go に比べてバイナリサイズがずっと小さくてマイコンとかに向いてると話していた。
次に https://play.tinygo.org の話になって、machine パッケージを import すると tinygo のコードからエミュレーションされたマイコンボードの LED を点滅させられるとデモしていた。
いろんなデバイスに対応していることも示していた。
エミュレーションの時は tinygo のコードを Wasm にコンパイルしてブラウザで動かして、 ネイティブコードにコンパイルしたものをダウンロードして実際のマイコンボードの flash に焼くとほら実際に動いたでしょとデモしていた。 RGB LED も光らせられるんだよと言っていた。
詳しくは https://aykevl.nl/2022/05/tinygo-preview を見てくれとのことであった。最初聞いたときはエミュレータで動かしたり実際のハードウェアで動かしたり訳がわからなかったが、 コンパイルターゲットの切り替えをうまく利用してるなと思った。
Cloud Native SecurityCon Europe day 2
今回は Wasm day を見ていたので SecurityCon は2日目のみレポートする。
Shrinking Software Attack Surface with WebAssembly & CNCF Wasmcloud
cosmonic という会社の人が話してる。wasmCloud をやっている会社である。
最初のうちは Wasm の話はでてこなくて、ベアメタル → VM → Container → Kubernetes と抽象化が進んできたけど、Kubernetes の抽象化は leaky だと話していた。
Container は小さくしたほうが attack surface を減らせると webshell の例をだして話した後で、App は大量の Library に依存しているので Container では解決できないと言っていた。
また、中国のビジネスのデータは中国に置かないといけないといった規制があるが、 Apps は portable でないので Container では解決にならないとまた言っていた。
wasm は portable かつ capability-based で deny-by-default だからセキュリティの問題も解決できると
App の 95% は Open Source コンポーネントで、NFR (non functional requirements) だそうで、これらの脆弱性を App 毎に解決しないといけない現状はだめで、 Platform レベルで解決できるべきだと言っていた。
これ以降は wasmCloud の宣伝っぽくなるのだが、wasmcloud application framework で それらのライブラリも Platform で面倒をみるからアプリ開発に集中できるよみたいなことをいってる。 wasmCloud だと NFR は 5% しかなくて、business logic だけ書けばいいとのことである。
次に distributed runtime の話になって、クラウドでもホストでも edge でも動くとか、 WASIよりももっと抽象的なインターフェイスを提供するんだとか言っていた。
最後に Case Study で、昨日の wasm day の adobe の (クラウド上と同じコードがブラウザの中でも動く) 話とか BMW の話をしていた。
Lightning Talk: Repurposed Purpose: Using Git's DAG for Supply Chain Artifact Resolution
Aeva Black が自分はセキュリティの専門家じゃないんだけど、と断ってから話していた。 最初は trust の定義について話していたが、gitbom 自体は署名と関係ない。
次に identity の話になって、artifact ID で管理するが ID はどういった性質を持つべきであるといった話をしていた。 git は Merkle tree を使っていて、git の object ID が artifact ID として使えるというのがこの発表のメインであった。
identity 以外にもいくつか解決しないといけない問題があるが、dependency は GitBOM Artifact Dependency Graph (ADG) で、metadata は SPDX などの SBOM から参照することで解決すると話していた。
詳しい情報は https://gitbom.dev にある。
Purple Teaming Like Sky’s the Limit – Adversary Emulation in the Cloud with Stratus Red Team
Datadog のセキュリティチームの話である。 blue team というのは防御側で、red team というのが攻撃側であるが、両者が協調してなにかをすることを purple teaming という言葉で表現しているようである。具体的にどう協調しているのかはよくわからなかった。
common attacker tactics (TTP) を understand, reproduce, detect するとかいってる。 再現するというのがこのプレゼンの主題で、再現することは検出ツールがちゃんと動いてるか確認するといった面でも重要である。
例として VPC flow logs が攻撃者に消されたことをどうやって再現するかといった話をしている。
クラウド環境での attack の再現は(長時間ドキュメントに頭かかえる必要があったりして)難しいといっている。 それを自動化するツール Stratus Red Team (http://stratus-red-team.cloud/) を紹介していた。 Go と terraform で書かれた attacks-as-code だとか attack library だとか説明していた。 AWS と Kubernetes を対象としているそうである。
攻撃者が攻撃の痕跡を隠すための操作を模擬した "Stop a CloudTrail trail" の説明もしていた。 まず CloudTrail を設定しないといけないので、ライフサイクルが複雑になっていて cold, warm, detonated の3状態あると話していた。
デモもあった。stratus コマンドというものがあるようである。 end-to-end detection testing を CI でやるとも話していた。
最後に、他のプラットフォームでも動くようにしたいとか、攻撃の種類を充実させたいといった Roadmap を説明していた。
Real Time Security - eBPF for Preventing attacks
eBPF でセキュリティイベントを検出したり防止したりする話である。 具体的にはネットワークトラフィックやファイルアクセス等で、カーネルサポートが必要である。 検出する方法としては他にも LD_PRELOAD, ptrace, seccomp があると話していたが、このプレゼンで扱うのは eBPF である。
syscall entry に eBPF kprobes を仕掛けてチェックするのは (kprobes の後で実際に使われるテータがユーザーランドからコピーされるので) TOCTTOU 問題があって回避されるのでだめであって、BPF LSM hook はそれをちゃんと考慮して作ってあって、LSM API が stable (カーネルバージョンに依存しない) だと言っていた。
ここで Cilium Tetragon の話になった。ここまで話してきた eBPF をつかってセキュリティ監視を行うプログラムで、ちょうどイベントにあわせてオープンソース化されたようである。 Tetragon という名前は巣の入口を守る蜂の名前からとったそうである。
Tetragon の機能で malicious event を見つけた瞬間にプロセスを殺せると話していて、 デモでは実際に /etc/passwd に write する直前に kill されたことを示していた。
KubeCon
Lightning Talks
Lightning Talk: Whyhappn Instead of Whodunnit: Avoiding the Term “Human Error”
最初に human error の歴史を話していた。 昔はシステムは悪くなくて人間が事故の原因と考えられていたけど、飛行機の安全性の研究が進んだら、人間は原因じゃなくてシステムがそもそも安全性を欠いていることが問題だと考えられるようになったそうである。 "human error" は意味のある分類じゃないとも言っていた。
後半では、Principles of High Reliability Organizations (Weick & Sutcliffe, 2007) を引用して組織はどうあるべきかといった話をしていた。
What Made Your Container Fat? Visualizing the Size of Container Layers
container image が突然大きくなって困ることがあるから container image の layer ごとにサイズを比較するツールを作ったから紹介するね、という話である。
webapp だから repository の path だけ指定すればほら動くよとかデモをしていた。 sunburst graph がでてきて、クリックするとレイヤの中を移動していろいろ見れるとかやってみせていた。 かっこいい。
https://github.com/dcermak/container-layer-sizes
Keynote
初日のオープニングキーノートで参加者数について、現地での参加が7,000人で Virtual が10,000人で sold-out だと発表されていた。コロナ前と同様とはいえないが相当賑いが戻っているだろうと感じた。
また、ウクライナの developer の話や Razom というウクライナを支援する NGO の話もあった。
詳細は省くが、kubeedge を積んだ LEO 衛星を軌道に投入した話や、 CERN の人の high throughput computing の話などもキーノートで話されていた。
一般セッション
How to Migrate 700 Kubernetes Clusters to Cluster API with Zero Downtime
Mercedes-Benz Tech Innovation という会社で、例の自動車会社の子会社だそうである。(見える範囲では) 会場はほぼ満員であった。キーノートでさわりを話していたものの詳報である。
terraform で作った Kubernetes クラスタを zero-downtime で cluster API で管理するクラスタに移行したという話である。 zero-downtime なのでクラスタのユーザは何もしないでよい (no-effort) だと言っていた。
タイトルの通り 700 クラスタを扱っていて、北京とシュツットガルトと北米にデータセンターをもっていて、 private も public もあると規模を説明していた。
cluster API は declarative API でプロビジョニングやアップグレードを管理してくれるもので、開発主体は cluster lifecycle SIG である。 移行の図がでてきて、Ansible で管理していた runtime deployment や addon を custom controller と flux で管理するようにしたと書いてあるが、彼等の環境特有のものをそうやって管理しているということのようである。詳細についての話はなかった。
次に実際の移行手順の話になった。3段階で移行させるが、3段階目で control plane を移行するときに失敗すると data loss がおきるので注意が必要だと言っていた。
1段階目では cluster 定義の yaml を書いて control plane を reconcile させるだけ。
2段階目では fake KubeadmControlPlane を使って reconcile をごまかすみたいな話をしている。 ここで、worker node の名前が cluster API の命名規則に従うように変わったけど何がおきてるかはよくわからなかった。
3段階目では既存の環境に合わせて KubeadmControlPlane を作ると cluster API が残りの操作をやってくれると言っていた。 最後に migration のために各段階で用意した dummy を消せば完了だそうである。
that's it とかいかにも簡単そうに話していたが、さすがに実際はこんな簡単ではないのではないかと思われた。
Pre-Drain とか Pre-Terminate が便利だったと教訓を話していた。
移行の timeframe はどうだったという質問があり、 700クラスタの作業に2週間くらいかかったとの答えであった。 Kubernetes のリリースにあわせて各段階をやったので完了するまで数リリースかかったと話していた。
質疑でチームの大きさを聞かれて、700クラスタの管理を30人くらいでやっていると答えていた。 他に、ベアメタルに関する質問もあったが、 OpenStack とか Public Cloud の上でやっていてベアメタルは使っていないそうである。 OpenStack Ironic も気にはしているが使ってないとのことであった。
Bypassing Falco: How to Compromise a Cluster without Tripping the SOC
falco の説明から始まった。runtime detection ツールの1つで、こんなルールを書くんだよと説明していた。 ルールを回避して悪いことができるかという話で、いくつか先行研究があると言っていた。
sensitive なファイルに対して symlink を作って symlink 越しでアクセスしたり、 実行ファイルの名前を変えて実行すると falco に検出されないとかいくつもの bypass を説明していた。
後半はデモして説明してる。 最初は検出できる例、次に bypass の例を示していた。
最後に、hooking point が大事だとか proc.name とかは bypass されるのを防ぐのが難しいとまとめていた。
使われていた手法は https://github.com/blackberry/Falco-bypasses にも詳しく書かれている。 falco 0.31.0 でいくつか対策されたと話していた。
Trampoline Pods: Node to Admin PrivEsc Built Into Popular K8s Platforms
最初に container escape の話をしている。今年も既に CVE がいくつも出ていて、今後も container escape は発生するだろうと言っていた。 攻撃者が container escape を実行したノード上の Pod は必ずしも攻撃の役にたたず、次に述べる Trampoline Pods があるかどうかがポイントだと言っていた。
タイトルにもある Trampoline Pods を、十分な権限をもっていて、他のノードに移動したりより高い特権を得たりといった踏み台に使える Pod として定義していた。 Trampoline Pods が daemonset で動いていれば攻撃者はかならずアクセスできるのでより危険だと言っていた。(そうでない deployment 等の場合はノードにあるかどうかは運まかせになる。)
Trampoline Pods の持つ権限について、attack class を定義して分類してどういった権限があったらどういう攻撃ができるかを説明していた。
良く使われる common infra daemonset を調べたところ、63% が powerful daemonset をインストールしていたそうである。全体の半数で container escape できれば admin 権限が手に入ると言っていた。結果は表でもまとめていた。ただし、 悪用するには container escape しないといけないし、既に修正されたものもあるので慌てるなと言っていた。
次に cilium を例に攻撃の説明をしていた。一つのノードで container escape すると他のノードの pod capacity をゼロにして cilium-operator を delete できて、その結果攻撃者のいるノードに cilium-operator を持ってくることができる。すると cilium-operator の token を使って ClusterRole が操作できて admin が手に入るそうである。デモ (速くてよくわからなかった) でもその手順を示していた。なお、既に cilium は修正済みだそうである。
これらの開発元に disclosure を行って修正をしてもらったそうである。 直しかたとしては、不要な privilege を削ったり、daemonset を使わないようにしたりといったものである。
グラフを出してよくなった (adminを取れる割合が減った) と言っていた。
詳しくは report (https://www.paloaltonetworks.com/resources/whitepapers/kubernetes-privilege-escalation-excessive-permissions-in-popular-platforms) に書いてあるそうである。
最後に rbac-police についても少し話していた。 Pod の RBAC を評価して powerful pods を見つけてくれるツールだそうである。
問題があいまいでわかりにくくなってきているから、 blind spot を減らすためにはっきりさせようとまとめていた。 質疑も活発に行われていた。
Logs Told Us It Was DNS, It Felt Like DNS, It Had To Be DNS, It Wasn’t DNS
最初に軽く datadog の説明をして、100-4000 ノードから成る Kubernetes クラスタをたくさん動かしていると言っていた。
metrics service を rollout したら問題が起きたという話で、DNS error がでてるし DNS の問題に違いないと思ったそうである。 node-local-dns が oom kill されてたので、node-local-dns の Pod のメモリふやしたけど metrics service のエラーは改善しなかった。
Network の問題ではなさそうだけど packet loss がある。 AWS のほうの問題 (instance limit) を疑ったけど違うようである。 次に conntrack limit を疑って、倍の大きさのインスタンスにすると改善したそうである。 conntrack countがやたらと多くて一体なんだろうと言っていた。
VPC flow logs をみてみたら ingress flow と egress flow が対応してなくて変で、 大量の SYN が送られてるとか話していた。最初のうちは SYN に対応した RST を返してるけど10秒経つとそれ以降は RST を返していない。alerting engine が SYN を送っているが、そのタイミングで metric service が rollout して古い Pod が消えるのでその IP パケットあての SYN が reverse path filtering で捨てられていると説明していた。
最後に gRPC の設定の話になった。 gRPC の round_robin load balancing policy がいけないとかいってる max_reconnect_backoff_ms も 300ms という短い数字に変更してあった。 自分の gRPC の reconnect の設定で syn flood してたということのようである。 設定をデフォルトにもどしたら直ったとのこと。
最後に教訓を話していた。ENA metrics と VPC flow log が役に立ったとか、いい勉強になったとかまとめていた。 内容が多岐にわたっていたためか時間切れで質疑なし。もしこんなデバッグが好きなら一緒に働かないか (we are hiring) といった言葉でしめていた。
まとめ
去年秋に北米で行われた KubeCon に比べて会場参加者はおよそ倍で、会場で行われている質疑をみていると、やはり現地で参加する意義はあるのだなと感じた。 ただ、#kubecovid というハッシュタグで知ったのだが、運悪く会場で covid に感染した人が少なからずいて、大変そうであった。
Wasm を流行らせようとしてる人達がいたり、数年前に聞いた cluster API を大々的に使った事例を聞いたりと、いくつか収穫があった。 他にも、secure software supply chain を構築するために必要なツールの整備も進んできているようであった。
次回はデトロイトで開催予定である。