今回は、Linux のリアルタイムスケジューリング実装である SCHED_DEADLINE の概要に触れた後、
最適化問題 IAP (Incremental Assignment Problem) 1 を核に据えて Unrelated 2 なマルチ・プロセッサモデルでの
SRT-optimality を証明した Unr-EDF
- 0. 本記事で使う用語に関して
- 1. マルチプロセッサ・リアルタイムスケジューリングと Linux
- 2. SCHED_DEADLINE
- 3. SCHED_DEADLINE 改造
- 4. 評価
- 5. 課題(改善ポイント)
- 6. まとめ
執筆者 : 田 幸一郎
0. 本記事で使う用語に関して
chrt(1) 等で設定するような、SCHED_DEADLINE 設定パラメタとしての period / deadline / runtime は、統一的に dl_period / dl_deadline / dl_runtime と表記しています。
また、本記事での「SRT-optimal」等の言い回しは、以下の定義に倣います(※2010 年代以降は比較的一般的に使われている言い回しに思えますが、念の為の言及です)。
[...]
Definition 2.3. A task set τ is HRT (respectively, SRT) feasible if and only if there exists a scheduling algorithm A such that τ is HRT (respectively, SRT) schedulable under A.
Definition 2.4. A scheduling algorithm A is optimal in an HRT (respectively, SRT) sense if and only if every task set τ that is HRT (respectively, SRT) feasible is HRT (respectively, SRT) schedulable under A.
[...]
1. マルチプロセッサ・リアルタイムスケジューリングと Linux
汎用的な Linux 上で(特にハード)リアルタイムなタスクを動かすには、PREEMPT_RT パッチ適用下においても、依然として困難(或いは、不安)が伴います 5。 スケジューリングのオーバヘッド、その他 OS ノイズ 6、状況に応じて幾つか要因があるかと思いますが、場合によってはスケジューリングアルゴリズムの選択肢の幅そのものが課題となることもあり得ます。
Linux には POSIX 準拠の SCHED_FIFO / SCHED_RR スケジューリングポリシー、更に SCHED_DEADLINE スケジューリングポリシーの、合わせて三種類のリアルタイムスケジューリングポリシーが備わっています。 例えば SCHED_FIFO を使えば、オーバランしない "行儀の良い" タスク群を、簡単なパラメタ設計を通じて、RM (Rate-Monotonic) / DM (Deadline Monotonic) といった Task-level Fixed-Priority (TFP) リアルタイムスケジューリングに落とし込む事が可能です 7。
一方、SCHED_DEADLINE は、EDF + CBS 8 ベースのスケジューリングポリシーであり、適切なパラメタ設定を行なえば、そのまま Job-level Fixed-Priority (JFP) リアルタイムスケジューリングである EDF の、ビルトイン実装が動作します。 EDF は、単一のプロセッサ環境で (HRT-) Optimal ですので、状況次第では単一プロセッサ単位でスケジューリングさせる(例. cgroup を使って Partitioned Scheduling 9)ことを選ぶことが多いかもしれません。その場合例えば、SRT タスクシステムに関しては別途、残ったプロセッサで Global Scheduling させるといった塩梅です。
EDF を Global Scheduling に適用した Global EDF (以後、GEDF) は、HRT-optimal ではないものの、SRT-optimal であることが知られています。 HRT-optimal な Global Scheduling アルゴリズムは幾つも提示されていますが(P-Fair, U-EDF, RUN, QPS, LLREF, DP-Wrap, etc.)、GEDF は、それらを除く他の "heuristic" なアルゴリズムの中でも、特にシンプルさ等の実用性を買われて、 実用シーンで幅広く採用されている(※勿論、SCHED_DEADLINE 含む)という認識です。 なお、近年では、Semi-Partitioned Scheduling、更には Adaptive Partitioning 10 といった方向性での研究も盛んなようですが、今回は触れません。というのも、今回の記事は、Unr-EDF(-like) な実装を試み、一般化されたマルチ・プロセッサモデルにおける SRT-optimality の実現を図る事に主眼を置いているからです。
いずれにせよ、現時点の SCHED_DEADLINE の GEDF において、Optimality を理論的後ろ盾のある形で担保したいのであれば、原則後述の Identical プロセッサモデルを前提とするのが安全です。 言い換えると、同一の処理性能の CPU からなるマルチプロセッサ環境で、Admission Control を有効化したままの状態です。 これは、場合によってはシステム構成、特にプロセッサ・アフィニティの設計において、足枷となり得ます。 例えば、レイテンシ・センシティブで且つリソース制約のあるマシンにおいて、一部の per-CPU カーネルスレッドと、幅広いアフィニティのクリティカルなタスク(群)の両方が、レイテンシに直接影響を与える場合、それらが混ぜこぜの状況で、最適な形でリアルタイムスケジューリングしたい事もあるかもしれません。しかも、それが big.LITTLE のようなヘテロ・マルチプロセッサ環境だったら・・・。
本記事では、最終的に Unr-EDF ベースで SCHED_DEADLINE の改造を試みる訳ですが、これは一般化されたマルチ・プロセッサモデルである Unrelated モデルをカバーする物です。
本記事では、プロセッサモデルに関しては
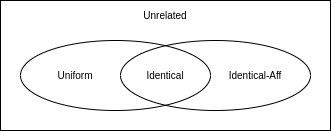
筆者の稚拙で怪しい改造の話に移る前に、次章で少し SCHED_DEADLINE の概要に触れたいと思います。 そもそも SCHED_DEADLINE は、その現状や今後の課題と解決状況、また近年のリアルタイムスケジューリングの理論的背景と照らし合わせると、依然事態が複雑であるように感じるからです。
2. SCHED_DEADLINE
2-1. 概要
大まかにいって、CBS + (G)EDF 実装です。つまり、EDF のアルゴリズムで CBS の reservation server をスケジュールさせるという物です。 平たく言うと、プロセス(タスク)は、CBS の reservation server が供給するバジェットの範囲でしか CPU 時間を消費出来無い為、時間的隔離(temporal isolation)が実現されます。 これによって、"行儀の悪い" タスクが他のタスクのリアルタイム性に悪影響を及ぼす可能性を排除します。汎用的な Linux において、これは嬉しいポイントです。
GEDF は、概念的には単一のランキューを使いますが、Linux のタスクスケジューリング機構におけるランキュー(rq)は、CPU 単位です。 rq に enqueue/dequeue し、rq からタスクを選択して、rq に紐づく CPU にスケジュール・実行させる、といった、Linux の大きな枠組みには倣いつつ、 GEDF のような挙動、つまり、使える CPU 群に、最もデッドラインの近いタスク群が丁度割り当てられるような形(i.e., グローバルなランキュー)を実現する為に、 push / pull 機構は欠かせない要素となっています。
CBS は、より細かく言うと、(revised-) H-CBS であり、hard reservation に対応したものです。 CBS には、余ったバジェットをうまく活用する(= 他のタスクが reclaim 出来るようにする) GRUB という亜種があり、 これを hard reservation 対応させた HGRUB の登場後、マルチプロセッサ対応させた M-GRUB 12 をベースにしたものが、当初より実装されていたようです。13 その後、GRUB-PA といって、余ったバジェットを DVFS に利用するような物も実装されました。 なお、GRUB-PA は、SRT-optimality を壊すことが
[Stephen Tang, James H. Anderson, and Luca Abeni. (2021)] 14 で指摘されています。 また、GRUB-PA を利用せずとも、そもそもヘテロ・マルチプロセッサ環境(※ CPU 周波数を固定して模擬した場合を含む)では GEDF は SRT-optimal ではありません。 もし仮に、GEDF で tardiness bound に気を使うような使い方をしている場合、注意が必要でしょう。
なお、H-CBS には、self-suspending task をカバーするよう拡張したもの、更に constrained-deadline なタスクモデルに拡張しようとしたもの等、亜種が幾つも登場してきました。 その内幾つかは SCHED_DEADLINE への試験的適用も図られたことのある物です。主なものを可視化してみると、以下のような感じになる認識です。 ざっくり、SCHED_DEADLINE の CBS が (revised-) H-CBS + M-GRUB であることが図示されています(※ GRUB-PA は描いていません)。
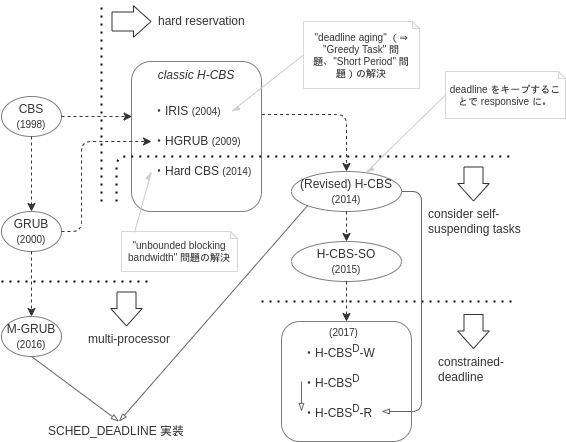
次節以降では、SCHED_DEADLINE にまつわる幾つかの重要と思しきポイントについて、ざっと触れていきます。
2-2. Admission Control
SCHED_DEADLINE の 公式ドキュメント に記載がありますが、bandwidth の合計がトータルで利用可能なキャパシティを超えないことを保証する役割を負っています。 bandwidth は CBS 文脈での言い回しであり、runtime / period で算出されます。 純粋に単一プロセッサに閉じた形で SCHED_DEADLINE を使い(= Partitioned Scheduling)、全てのタスクが implicit-deadline タスクの場合、これは Optimality の条件と一致することになります。 もし複数プロセッサで Global Scheduling させる場合、Admission Control がタスクのプロセッサ・アフィニティに関して APA(Arbitrary Processor Affinities)を弾くので、 結果として SRT-optimality が理論上は保証されます。但し、Identical プロセッサモデルとは言えない状況下において、SCHED_DEADLINE は UG-GEDF 15 的な挙動をする訳ではありませんので、そうした保証は出来無くなります。
なお、Linux において、理論上 SRT-optimal なケースにおける tardiness bound は、(もし計算したいのなら)ユーザが自ら計算するしかありません。 一部の特殊なタスクモデルに特化した物を除いて、GEDF は未だ完全にタイトな tardiness bound の導出はなされておらず、執筆現時点では一般的には "Harmonic bound" 16 が最もタイトであると認識しています。
2-3. GRUB 及び GRUB-PA
カジュアルに言ってしまうと、余った CPU 帯域を、アクティブな皆(Reservation Server)で分け合おうという GRUB(M-GRUB を SCHED_DEADLINE に落とし込んだ物)、 分け合うのではなくてリアルタイム性を損なわない範囲で CPU 周波数を下げられるだけ下げようとする GRUB-PA、の2種の GRUB が実装されています。
システムワイドな cpufreq governor が schedutil か否か、及び、タスク単位で設定出来るスケジューリングフラグの一種である SCHED_FLAG_RECLAIM の有無により、パターン分け出来ますので、一先ず表にしてみます。
| 通常ケース (cpufreq governor != schedutil) | schedutil | |
|---|---|---|
| 通常のタスク | (note: still capacity-aware) |
(GRUB-PA) |
SCHED_FLAG_RECLAIMをセットしたタスク |
(GRUB (≒ M-GRUB (Sequential))) |
想定範囲外 |
- cpufreq governor を schedutil にした時、GRUB-PA が有効になります。 この時、schedutil が宜しく負荷に応じて CPU 周波数を調整してくれる為、SCHED_DEADLINE の実装中 capacity-aware な runtime 更新箇所(参照: source)が 自然と GRUB-PA になります。
- GRUB は、(schedutil ではない cpufreq governor を使用している "普通の" 状況で)
SCHED_FLAG_RECLAIMで有効化出来ます。 (see. sched_setattr(2) ) オリジナルの M-GRUB(Sequential reclaiming)に近しい実装ですが、SCHED_DEADLINE 向けに細かい工夫を加えているようです。grub_reclaim()の意図がぱっと見て分かり辛いので、図にしてみました。
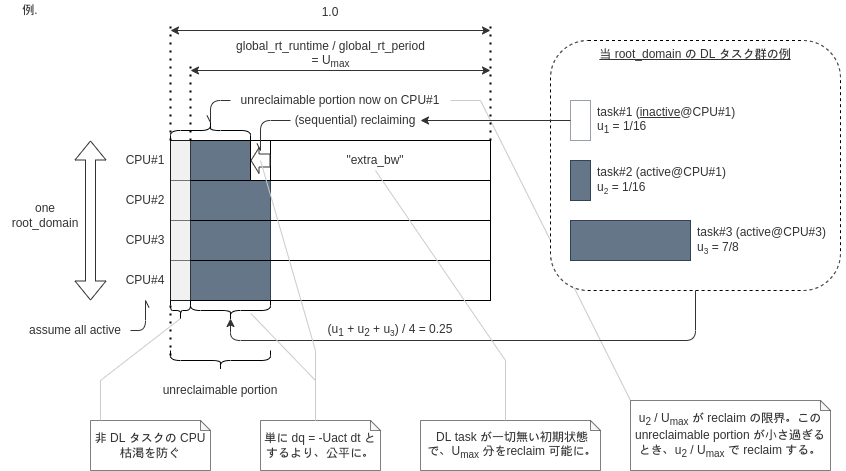
ところで、GRUB-PA で一種の DVFS 対応しているという訳ですが、DPM (Dynamic Power Management) に関しては特に対応していないようです 17。 例えば、CPU Idle governour と連携して、要求されるレスポンスタイムの上限の担保が出来る範囲で、C-State の深さをコントロールする等出来たら面白そうですね。
2-4. Capacity awareness
SCHED_DEADLINE は Uniform / Unrelated プロセッサモデルにおいて SRT-optimal なスケジューリングアルゴリズムを実装している訳ではないものの、 前項で言及した GRUB-PA において、capacity-awareness はその構成要素でした。 以前の ARM の EAS(Energy Aware Scheduling)関連の取り組みだけでなく、昨今の Intel Hybrid Technology のトレンド等からも、今後も重要視され得る要素な気がします。 SCHED_DEADLINE には、執筆時点のアップストリームで、以下2点においても capacity-aware です。
- Capacity-aware admission control
- Capacity-aware CPU selection on wake-up/push/offline-migration
1点目は、
2-5. 公に指摘されている課題等
ここでは、幾つか外部の資料や論文を列挙しておきます。
- (slide) (2017) SCHED_DEADLINE: What's next?
- (slide) (2019) SCHED_DEADLINE: What’s next (?)
[Tang, S., Voronov, S., Anderson, J.H (2019)] 11[Stephen Tang, James H. Anderson, and Luca Abeni (2021)] 14- etc.
なお、実装面では、主立って取り上げられていたように感じる以下2つの課題に関しては、筆者の知る限りにおいては、アップストリームに至る現実解は未だ出ていないという認識です。
Proxy Execution
- M-BWI 19 のアイデアを具現化しようとしているようなパッチが公開されているようです: https://github.com/jlelli/linux/commits/experimental/deadline/proxy-rfc-v2
- 昨今は少なくとも公には、議論・実装が進んでいないように見えます。オフラインで何か進捗しているのかどうかは、筆者は存じません。(参考: https://lkml.org/lkml/2018/10/9/431、https://lwn.net/Articles/793502/)
Hierarchical CBS
- こちらも昨今特に動きが無い物と認識していますが、関連リンクを貼っておきます:https://lkml.org/lkml/2017/3/31/658
- 公開されているパッチ: https://github.com/lucabe72/LinuxPatches/tree/Hierarchical_CBS-patches
2-6. アドミン視点で留意すべきポイントの整理
(a). HR_TICK_DL
有効化すると、CBS のバジェットを消費しきる見込みのタイミングで、scheduler tick を(余分に)発動させることが出来ます。
SCHED_DEADLINE は、様々なタイミングで CBS のバジェット消費の記録・更新を行うのですが、scheduler tick 毎にもそれらが実行されます。
よって、CBS の精度を担保する為に、hrtick は有効化しておくと良いです。精度が悪いと、replenish や throttle のタイミングに悪影響が出てしまいます(※典型的には、オーバランに繋がり、temporal isolation も破られる)。
デフォルトでは有効化されていませんが、CONFIG_SCHED_HRTICK=y の時、以下で有効化出来ます。
# 事前確認 grep CONFIG_SCHED_HRTICK /boot/config-`uname -r` # kernel バージョン >= 5.12 の場合 echo HRTICK_DL | sudo tee /sys/kernel/debug/sched/features # kernel バージョン < 5.12 の場合 echo HR_TICK | sudo tee /sys/kernel/debug/sched/features
筆者は、特段の事情が無い限り(例. オーバヘッドが問題となるレベル)、HR_TICK_DL は有効にしておいて良いものという認識です。 特に、設定したい dl_runtime パラメタがミリ秒未満オーダの時、原則必須事項と捉えて良いのではと思います。 なお、hrtick は最小でも 10 マイクロ秒後の割込み発動になります。
(b). kernel.sched_deadline_period_{min,max}_us
max の方はさておき、dl_period パラメタの設定を 100 マイクロ秒未満にしたい場合、min パラメタの値を下げていく必要があります。 下げれば下げる程、短い最小ジョブ到着間隔の SCHED_DEADLINE タスクを許容することになりますが、 環境次第では 10 マイクロ秒でも十分実用可能かと思います。 頻繁なタイマー割込みのオーバヘッド含め、実際の環境で検証してみると良いのではないかと思います。 なお、10 マイクロ秒未満に設定するのは流石におすすめできません。先に述べた hrtick は最小でも 10 マイクロ秒の設定しか出来無い為、オーバランが頻発し得ます。
(c). kernel.sched_rt_runtime_us=-1
Admission Control が効かなくなる代わりに、私達は自由の世界に解き放たれ、任意のプロセッサ・アフィニティの設定(APA)も可能になります。
個人的には、大体のケースで、大体経験則的に決して悪くない性能が出るという感触です。
どうしても、Identical-Aff / Uniform-Aff なプロセッサモデルの環境で動かす必要がある場合、
タスクシステムが SRT であると言えるのであれば、一旦 kernel.sched_rt_runtime_us=-1 で試して、ジッタが許容出来そうなレベルか
様子見してみるのも良いのでは?と個人的には思います。
なお、当然ですが、CPU 枯渇させる可能性のあるような SCHED_FIFO / SCHED_RR タスクが存在する場合、大変危険な設定です。
3. SCHED_DEADLINE 改造
3-1. 実装方針
今回の改造の目的は、Unr-EDF をベースに、SCHED_DEADLINE を、ヘテロ環境や任意のプロセッサアフィニティを(SRT-optimality の観点で)カバーする、汎用的なスケジューラに拡張することです。 中核の GEDF を Unr-EDF に置き換えることがメインのタスクになります。 Unr-EDF を忠実に具現化している訳ではないので、(安全の為)以後今回の改造成果物を Hungarian-SCHED_DEADLINE と呼びます(※本記事のタイトル「ハンガリアン SCHED_DEADLINE」に対応しています)。 例えば、そもそもアップストリームの「H-CBS (+M-GRUB(-PA))」は維持していますので、既に Unr-EDF から乖離しています。
今回、Linux カーネル tip ツリー sched/core ブランチの、2022年7月10日時点で最新の commit c02d5546ea34 に差分を当てる形で実装しました。20
■ 実装: github.com
commit e5a5ad7d71672f4e2dbb5859b351e36f5c2d9419
Author: Koichiro Den <xxxxxxxxxxxxxxxxx>
Date: Wed Jul 13 15:56:58 2022 +0900
sched/deadline: replace GEDF schduler with a Unr-EDF-like one
initial commit.
include/linux/sched.h | 20 +++
kernel/sched/build_utility.c | 1 +
kernel/sched/core.c | 74 ++++------
kernel/sched/deadline.c | 1472 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++---------------------------------------------------------------------------------------------------
kernel/sched/debug.c | 2 -
kernel/sched/hungarian.c | 480 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
kernel/sched/hungarian.h | 49 +++++++
kernel/sched/rt.c | 2 +-
kernel/sched/sched.h | 68 +++++-----
kernel/sched/topology.c | 4 +
tools/sched/ac.py | 275 +++++++++++++++++++++++++++++++++++++
11 files changed, 1623 insertions(+), 824 deletions(-)
差分の中核となる (A)~(C) に関して、大まかな実装イメージを示します。
(A). kernel/sched/deadline.c
(*source)
DL (Deadline) スケジューリングクラスの sched_class 実装内部に手を加える形で、
その "脳味噌" とも言える per-CPU な rq 毎に存在する2個の赤黒木の代わりに、新たな "脳味噌" として Root Domain 毎の二部グラフを新設しています。
大雑把に言うと、rq に enqueue/dequeue すると、Root Domain の二部グラフのマッチングに更新(IAP)が掛かる形です。
IAP は次項 (B) に対応する hungarian.h が提供する関数を利用する形を採っています。
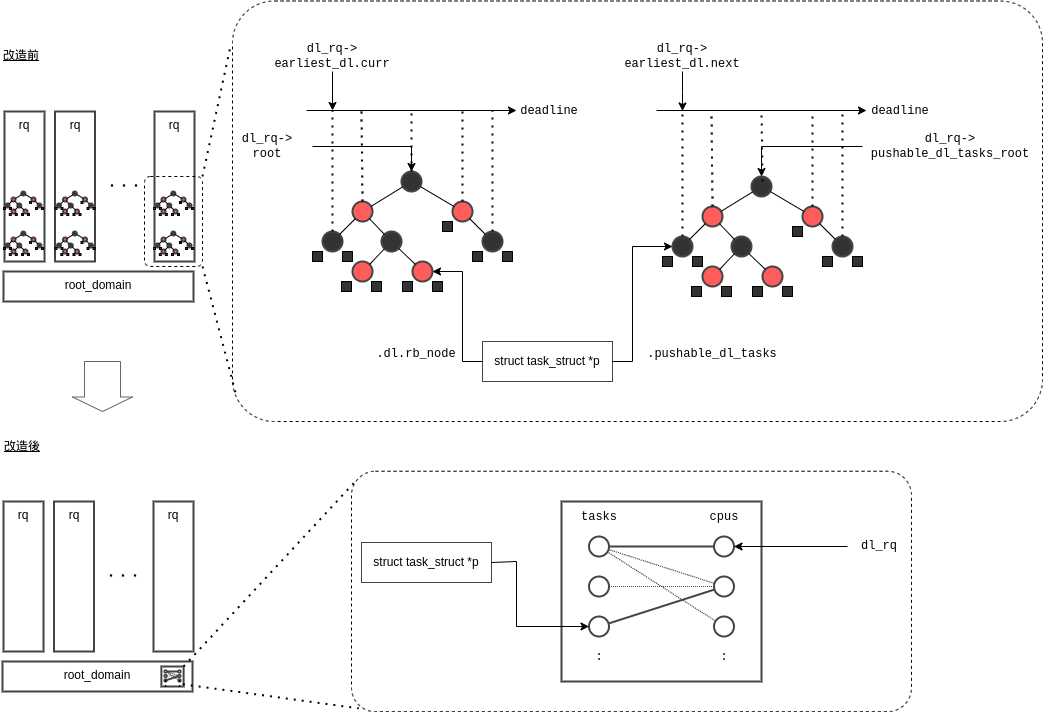
push/pull 機構に関しては、外枠の関数名は維持していますが、その役割、実装は全く異なった物になっています。
元々、rq が per-CPU である一方でグローバルな EDF を実現する為に、push/pull が必要になっていた訳ですが、
今回の実装では、そういった必要性はありません。常に、二部グラフのマッチングが、その時点での正解の割当てを一意に返します(参照:source)。
一方で、数多のパターンがありますが、結果として sched_class の API を通じて rq へ enqueue する際、その rq が正解のマッチングと異なる場合、正しい rq に付け替える必要があります。
その為、push/pull 機構の外枠の関数名をそのまま使用し、中身に付替え実装を施しています。rq の探索は ということになります。
なお、enqueue/dequeue で二部グラフのマッチングに更新を掛けると、当然その実行元 CPU 以外の他の CPU 群(=同一 Root Domain の他の CPU 群)においても、最新のマッチングに合わせて context switch させる必要が生じ得ます。この時、紐づく rq に関して、resched_curr で再スケジューリングの必要性を通知します(必要に応じて IPI 発行)。対象 CPU で、マッチング更新直前まで非 DL タスク(※ idle タスク含む)が走っていた場合も同様です。一方、現実的には non-preemptible セクションの長さ次第で、先に述べた context switch の実行には遅れが出てしまいますが、今回の改造においては、既に話が十分ややこしくなっている為、この点は一旦無視しています。
(B). kernel/sched/hungarian.c
(*source)
IAP 1 をカーネル内に実装した物です。(A) の kernel/sched/deadline.c がその中核で使用します。
最 "大" 費用完全マッチングを主双対法で解くハンガリアン法(Hungarian Method)を、DL タスク及び rq の増減に応じて、インクリメンタルに動かすような物で、
一方の頂点集合が DL タスク群、他方の頂点集合が(同一 Root Domain に属する)rq 群に対応しています。
DL タスクが増減(enqueue/dequeue)するとき、一方の頂点集合に対して DL タスクが追加・削除され、
rq が増減(rq_online() / rq_offline())するとき、他方の頂点集合に対して rq が追加・削除されるイメージです。
Unr-EDF 3 「II. BACKGROUND」 > 「A. System Model」に倣い、 とした上で、必要に応じて、接続する辺の重みが全て 0 のダミーの頂点を導入します。
先に、DL タスク及び rq が追加・削除されるイメージ、と述べましたが、この内、DL タスクの追加・削除が普段頻繁に実行される物です。 そして、多くの場合、DL タスクの追加は、ダミーのタスクを1つ選んで重み更新しアクティブ化すること、DL タスクの削除は、アクティブなタスクの重みを更新し非アクティブ化すること(※いずれも、Hungarian Method の "Stage" を1回分走らせる)、に対応しています。
(C). tools/sched/ac.py
(*source)
本来であれば、sched_setattr(2) 延長等、カーネル内 __sched_setscheduler() 呼出しで admission control を実現したいところではあります。
一方、Unr-EDF は tardiness bound 導出の為に、途中で線型計画問題を解く工程が必要です 21。これをカーネル内で実装するのは、個人的には無理がある気がしています。
かといって(何らかの、周囲の sleepable なコードセクションから)Usermode Helper を使ってユーザ空間のチェックツール(※線形計画ソルバーを使いたい、python で楽をしたい)を叩くのも、アクロバティック過ぎる気もします。
そこで、一旦は簡易スクリプトを用意するにとどめました。ユーザが chrt(1) 等で新しいパラメタを適用する直前等に利用する想定です。
3-2. 計算量
Unr-EDF のスケジューリングを実現する為に、その対象となる CPU の範囲で共有される二部グラフを内部で設ける必要がありますが、Root Domain 単位とする事が自然かと思い、そうしています。 IAP の計算量及び、並列化出来無いポイント("serial fraction")が、一見すると実用面で不安です。
アップストリームの SCHED_DEADLINE における pick_next_task 実装は、先に述べたように rq 毎に二つの赤黒木を持ち、頻繁に実行される追加・削除が、時間計算量の支配項となる訳ですが、 まで膨らんでいます。
今回の改造と比較してみます。(※タスク数 n、プロセッサ数 m)
| SCHED_DEADLINE | Hungarian-SCHED_DEADLINE | |
|---|---|---|
| .pick_next_task | ||
| > pull tasks | ||
| > pick_next_task_dl | ||
| > update pushable_dl_tasks | - |
Hungarian-SCHED_DEADLINE は、例えば IIAA 22 のアプローチを適用することで、幾つかのケースに限定すると まで落とせる一方、最悪計算量は変わらない為、メニーコアで Global Scheduling させる場合、厳しいことになる筈です。
但し、わざわざリソースの過少使用(under-utilization)を避けたり、SRT-optimality を求めて Global Scheduling させるような状況としては、どちらかというとモバイル端末環境等が想像され、数百コア以上のメニーコア環境で SCHED_DEADLINE を Global Scheduling に使う事は無さそうと思います。
ですので、IIAA やそれに変わるアプローチを追い求めるというより、筆者は
EM_MAX_COMPLEXITY と同様のアプローチで閾値を設けてあげて、切り換えるというのが、落としどころとして好ましいアプローチなのではないかと考えます。
3-3. sysctl 可変パラメタ
Hungarian-SCHED_DEADLINE では、1点だけ、(新たな)sysctl の可変パラメタを追加しています。
オリジナルの Unr-EDF の 関数を、オンラインで変更出来るようにしています。
sysctl -w kernel.sysctl_sched_dl_phi_mode={0,1,2}
- mode=0 : オリジナル(※デフォルト設定)
- mode=1 : t の近似に、
ではなく
(latest pseudo-release)を使用 23
- mode=2 : mode=1 に加え、LLGF (Least Laxity-Group First 24)-like な挙動に変更
3-4. Admission Control とその位置付け、及び tardiness bound 算出
3-1 の (C) で述べたように、Admission Control 用に簡易ツール ac.py を設けました。元々カーネルに存在する Admission Control は、原則的にはそのまま残しているので、プロセッサモデルが Identical モデルを逸脱したときは単に、 明らかな over-utilization を防ぐ 程度の意味しか持たせていません。 同簡易ツール ac.py で、feasibility チェックから tardiness bound 算出までをカバーしようとしています。 結局評価に使っていない為、実装が完了していない部分もありますが、ざっくりと、
- Root Domain のリストを取得
- 各 Root Domain 毎に、
- 現存 DL タスク群のリストを取得
- プロセッサモデルを特定する
- プロセッサモデルが
- Unrelated の場合 ⇒
を導出(
[S. Tang, S. Voronov and J. H. Anderson (2021)] 3 中式 (12)、LP-Feas)した上で、であればそのまま tardiness の算出(同 3 中式 (21))
- Uniform/Identical-Aff の場合 ⇒ feasibility をチェック(※ Uniform の場合、
[S. Funk, J. Goossens and S. Baruah (2001)] 25 Theorem 4、但し原則 implicit-deadline periodic タスク想定。Identical-Aff の場合、MF-Test (or UB-Test)[Sergey Voronov and James H. Anderson (2018)] 26 またはオリジナルの APA-Feas 27)した上で、(HP-LAG-Compliant な振舞いが出来ている事を仮定して)tardiness 算出 - Identical の場合 ⇒ (GEDF と同等の振舞いが出来ている事を仮定して)tardiness 算出(e.g., harmonic bound)
- Unrelated の場合 ⇒
といった具合の物になると想定しています。
4. 評価
アップストリームの SCHED_DEADLINE と比較評価してみます。 実用的に作り込まれた物と、筆者のアドホックなおもちゃを比較評価しても、大した意味は無いのですが、課題を探る為にも性能評価してみます。
4-1. 評価環境
手元にあったノート PC 1台を使います。本来であれば、big.LITTLE 等のヘテロな環境で検証したかったのですが、今回は見送りです。
- Lenovo ThinkPad T470s
- distro: Fedora 34
- isolcpus=1-3 nohz=on nohz_full=1-3 rcu_nocbs=1-3
- CONFIG_NR_CPUS=8
- CONFIG_CPU_FREQ_DEFAULT_GOV_SCHEDUTIL=y(scaling_governor はそのまま schedutil)
- HR_TICK_DL 有効
- lscpu 出力 ▶クリックで展開
4-2-(a). Identical プロセッサモデル
SchedCAT 付属ツールを使用し、Stafford の Randfixedsum アルゴリズムで、0.1~3.0 の utilization (※ 0.1 刻み) に対して 10 パターンのタスクセットをランダム生成し、Lag を比較してみます。
Lag を評価軸にしているのは、単に static tracepoint を使いお手軽に計測出来る為です。(※但し、scaled_delta_exec を吐く為に、DL では使われていない CFS 向けのフィールド vruntime をオーバーロードしています。参照:source )
rt-app を使い、implicit-deadline periodic な CBS の Reservation Server を動かし、理想的なスケジュールからのズレを scheduler tick における "runtime" 更新状況と照らし合わせる事で、Lag 近似値を計測します。
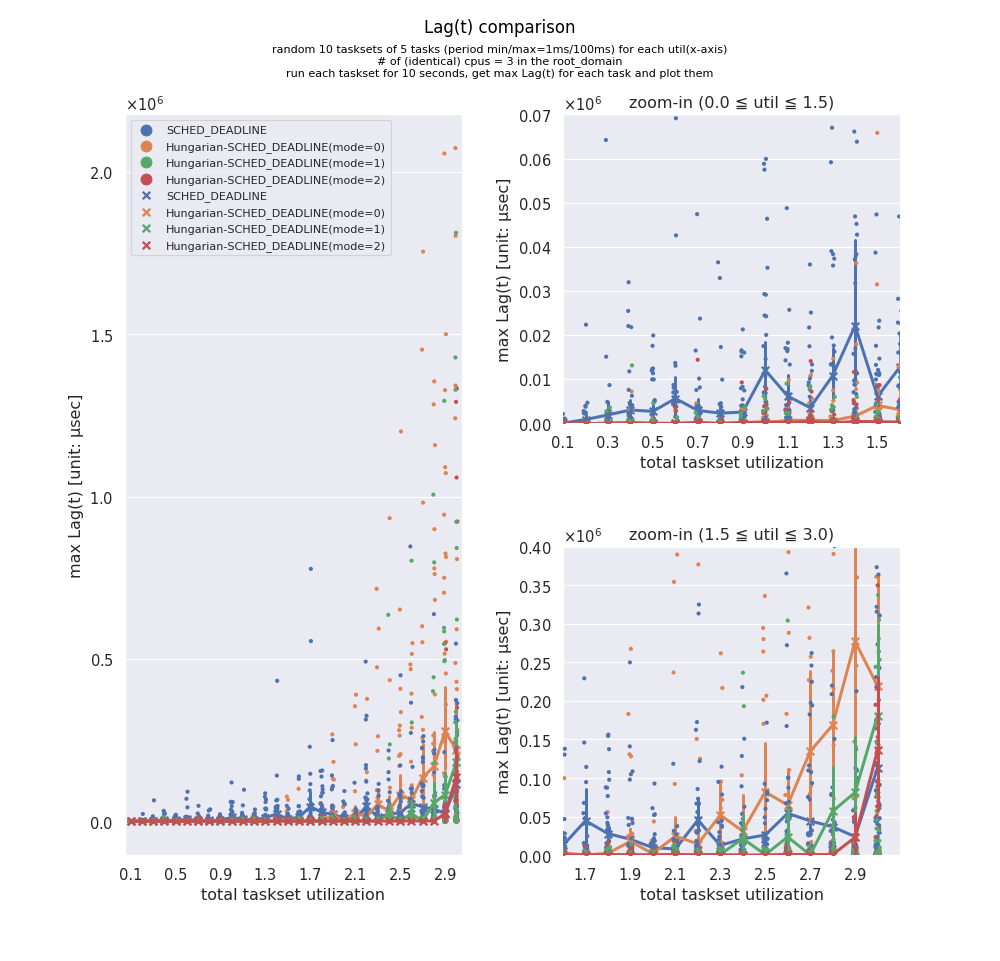
- 特に total utilization が 0.0~1.5(0~50%)と低めの時、mode=1, mode=2 が健闘している事が分かります。
- 一方、total utilization が 1.5~3.0(50~100%)と高めの時、mode=0, mode=1 は暴れ出し、SCHED_DEADLINE に負ける事もしばしばです。
- mode=2 は、total utilization=2.9 を超えると概ね SCHED_DEADLINE と同等ですが、それまではグラフで見えるスケールですと、Lag が極めて低く抑えられている事が分かります(x軸に張り付いている赤線)。
Hungarian-SCHED_DEADLINE の作り込みはまだまだ甘いにもかかわらず、LLGF 的要素を取り込んだ mode=2 がここまで良い成績を出したのは想定外でした。しかも、そもそも Identical モデルでは、Hungarian-SCHED_DEADLINE はオーバーキルです(持ち味を活かしきれないので、多少 SCHED_DEADLINE に負けても構わないつもりでした)。未だガラクタの筈なので、もう少し慎重に、多様なワークロードで大量の測定をした方が良いかもしれません。
4-2-(b). Identical-Aff プロセッサモデル
これ以後(=前項の Identical モデルを除き)、(b) 〜 (d) においては、ランダムにどうタスクシステムを大量生成すべきか、すぐには分からなかった為、適当に1つのケースを取り上げて比較計測していきます。つまり、ちょっとした "味見" 程度に過ぎません(pinch of salt :p)。以下グラフは、30 秒間、(グラフ内上部に記載の)ワークロードを印加したときの、Lag 近似値の観測値の散布図です(※観測点が多いので繋がっているように見えます)。
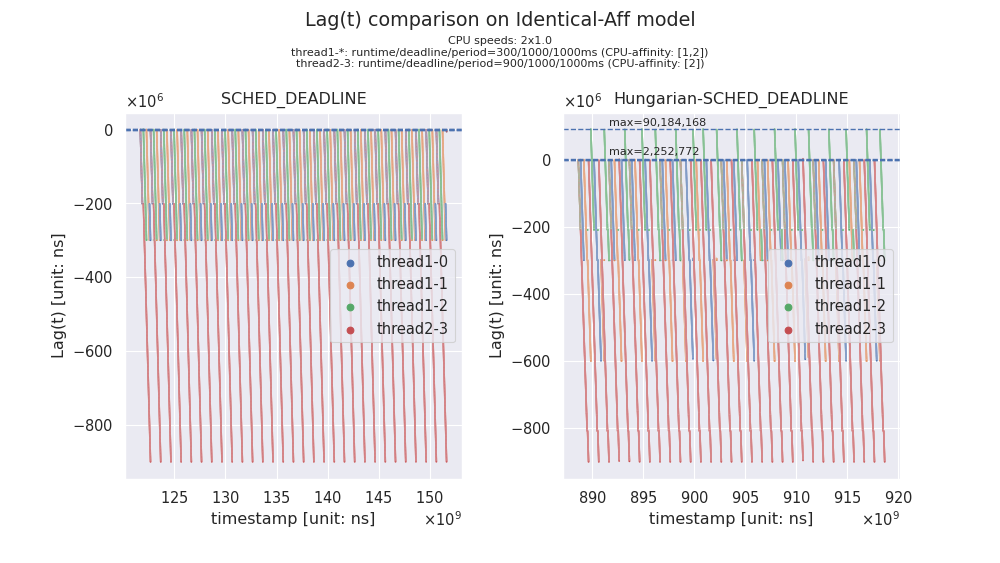
Hungarian-SCHED_DEADLINE の方は、最大約 90 ミリ秒の Lag が観測されている為、明らかに deadline miss を起こしている一方で、SCHED_DEADLINE は概ね deadline miss は起こしていないと捉えて良さそうです。詳細に調査する時間は無い為、今後の課題とし、次に進みます。
4-2-(c). Uniform プロセッサモデル
今回、Uniform プロセッサモデルを実現出来る環境が手元にありません(※ x86-64 で且つ、"BusyMhz" 一定で、Frequency Invariance スケーリングも活用出来ない状況)。
残念ですが、アドホックに、arch_scale_freq_capacity に手を入れて、Uniform プロセッサモデルを模して計測しています(本当は全 CPU で同一の "BusyMhz" なのにもかかわらず、片方だけ 0.5 倍のスピードにスケーリングさせます)。
印加するワークロードがきちんとしたリアルタイムタスクセットであった場合、実際には(大体)1.0 倍のスピードでタスクが捌けてしまうので、この対応は非常にまずいのですが、今回は rt-app を使って単に長時間のビジーな run イベントを動かすだけですので、CBS の挙動(※バジェットの更新)にスケーリングが反映されればよく、たまたま問題にはなりません。
以下では、合計 1.5 のキャパシティの Root Domain (2つの CPUをカバー)において、合計で 1.46 の(ぎりぎりの)Utilization のタスクセットをスケジューリングしてみます。
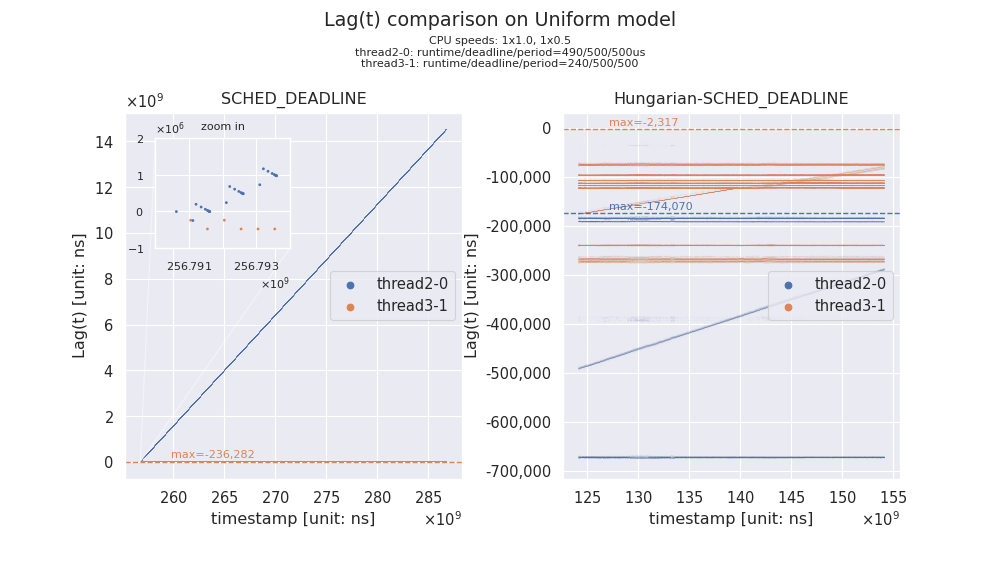
SCHED_DEADLINE では、Lag(t) 近似値が膨らみ続け、上グラフのように Unbounded tardiness と思しき状況に陥ってしまうことがあるようです。 一方、Hungarian-SCHED_DEADLINE においては、うまく対処出来ているように見えます。
4-2-(d). Unrelated プロセッサモデル
前項と同様の似非ヘテロ環境に、APA なタスクセットをスケジューリングしてみます。 中身はシンプルで、以下のように3つのタスクのみから構成します。 thread1-0 は速い方の CPU に、thread2-1 は遅い方の CPU に固定された状態で、いずれの CPU でも動ける thread3-2 を追加してあげて、様子を見ます。
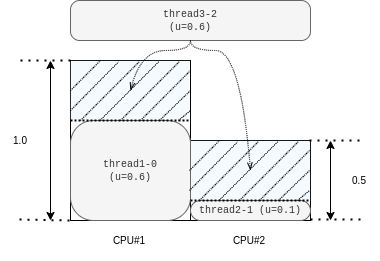
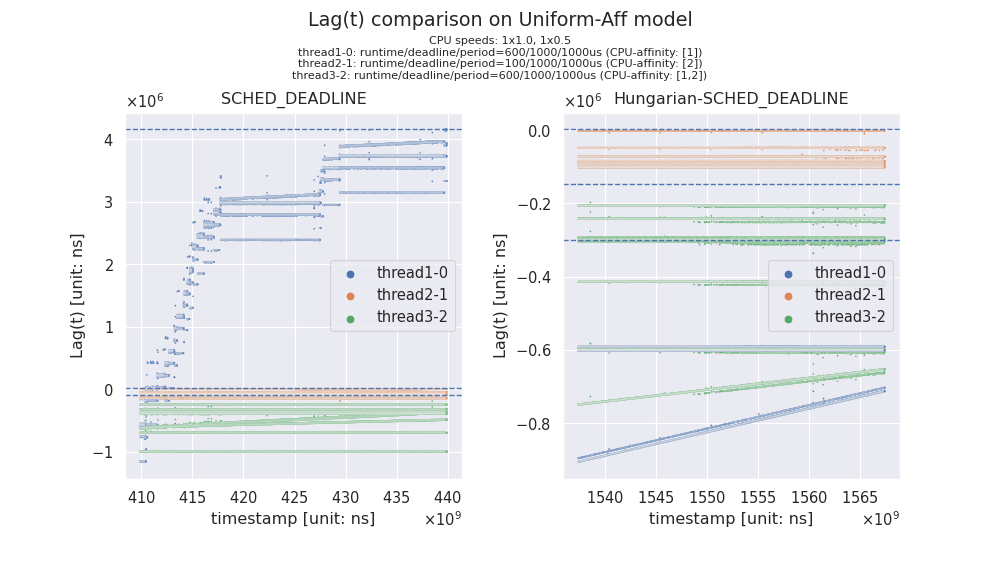
SCHED_DEADLINE では、やはり Unbounded tardiness と思しき状態に陥っている一方、Hungarian-SCHED_DEADLINE ではうまく対処出来ているように見えます。
5. 課題(改善ポイント)
Unr-EDF は implicit-deadline (L&L) タスクを想定している一方、SCHED_DEADLINE のインターフェースは(Reservation Server のパラメタですが)constrained-deadline タスクモデルをカバーしています。今回の改造には実用上影響は無いものの、新設した tools/sched/ac.py は、一先ず utility を density に入れ替えたような、pessimistic な物にしてあります(※当然ですが、implicit-deadline タスクを動かす場合には、差異は出ません)。仮に runtime == deadline なタスク(C=D スプリット的な)が1つでもあれば、
今回の実験的実装においては、ある1 スケジューリングイベント時に、空き CPU が存在する場合、マイグレーションを削減する工夫を入れています。一方、同一のスピード(
)のプロセッサが多く存在する場合、ある種の scheduling cascade を愚直に発生させる必要が無いケースが出てきます(aka. "limited unrelated multiprocessors")。こうした場合、マイグレーション削減余地はありそうです。
- その他、完全に実装マターですが、バグや改善すべき項目が多々あるかもしれません。見えているところですと、例えば、
MAX_VERTICESマクロ変数を使って、メモリ領域確保に関して楽をしています。無いとは思いますが、仮にメニーコア環境で動かす場合、これは問題になるので直す必要があります。
6. まとめ
Linux とリアルタイムスケジューリングについて考える、良いきっかけになりました。
-
I. H. Toroslu, and G. Üçoluk. Incremental Assignment Problem. Information Sciences 177, no. 6 (March 15, 2007): 1523–29. doi: 10.1016/j.ins.2006.05.004↩
-
今回の実装は、CPU Invariance / Frequency Invariance スケーリングでプロセッサのスピード(
)を表現している為、 https://www.kernel.org/doc/html/latest/scheduler/sched-capacity.html#representation-caveat で言及されている点と同様ですが、結果として Uniform-Aff プロセッサモデルまで対応しているといった方が相応しい物になっています。Unrelated プロセッサモデルがそれを一般化しており、Unr-EDF が本質的に Unrelated プロセッサモデルに対応しているので良いのですが、現状の CIE (CPU Invariance Engine) / FIE (Frequency Invariance Engine) よりもう一段階踏み込んだ粒度の何かでスピードを表現出来ると、より真価を発揮出来そうです。↩
-
S. Tang, S. Voronov and J. H. Anderson, “Extending EDF for Soft Real-Time Scheduling on Unrelated Multiprocessors,” 2021 IEEE Real-Time Systems Symposium (RTSS), 2021, pp. 253-265, doi: 10.1109/RTSS52674.2021.00032↩
-
Brandenburg, B.: Scheduling and locking in multiprocessor real-time operating systems. Ph.D. thesis, The University of North Carolina at Chapel Hill (2011)↩
-
大前提として、本記事では各種 Cokernel アプローチ(RTLinux、Xenomai、etc.)や、商用の Real-time Linux 等には触れません。↩
-
Linux カーネル 5.17 で、Real-Time Linux Analysis (RTLA) tool が取り込まれました。これは、5.14 で取り込まれた OSNOISE Tracer も利用しています。↩
-
但し実用的には、単に最高優先度で動かしたい、遅延幅・ジッタを抑制したい、といった目的1点で使われることが多いように感じます。勿論、CPU を枯渇させないよう注意が必要です(※ 最悪、RT タスクのスロットリングに頼る等)。↩
-
原論文を当たる以外では、個人的には、ある種教科書的な本「Butazzo, G.C.: Hard Real-Time Computing Systems: Predictable Scheduling Algorithms and Applications, 3rd edn. Springer, New York (2011)」の 6章 DYNAMIC PRIORITY SERVERS の説明がとても分かり易い気が致します。↩
-
cgroup の使用例に関しては公式ドキュメントに記載がありますので、ここでは触れません。参照: https://www.kernel.org/doc/html/latest/scheduler/sched-deadline.html#sched-deadline-and-cpusets-howto↩
-
例えば、A. Stevanato, T. Cucinotta, L. Abeni and D. B. de Oliveira, “An Evaluation of Adaptive Partitioning of Real-Time Workloads on Linux,” 2021 IEEE 24th International Symposium on Real-Time Distributed Computing (ISORC), 2021, pp. 53-61, doi: 10.1109/ISORC52013.2021.00018.↩
-
Tang, S., Voronov, S., Anderson, J.H.: GEDF tardiness: Open problems involving uniform multiprocessors and affinity masks resolved. In: 31st Euromicro Conference on Real-TimeSystems, ECRTS 2019, July 9-12, 2019, Stuttgart, Germany, pp. 13:1–13:21 (2019)↩
-
Luca Abeni, Giuseppe Lipari, Andrea Parri, Youcheng Sun. Multicore CPU Reclaiming: Parallel or Sequential?. 31st ACM Symposium on Applied Computing, Apr 2016, Pise, Italy. doi: 10.1145/2851613.2851743↩
-
M-GRUB のペーパの著者と、オリジナルの GRUB Linux 実装のアップストリーミングをされている方は、同一人物です。↩
-
Stephen Tang, James H. Anderson, and Luca Abeni. 2021. On the Defectiveness of SCHED_DEADLINE w.r.t. Tardiness and Affinities, and a Partial Fix. In 29th International Conference on Real-Time Networks and Systems (RTNS'2021). Association for Computing Machinery, New York, NY, USA, 46–56, doi: 10.1145/3453417.3453440↩
-
K. Yang and J. Anderson, “On the Soft Real-Time Optimality of Global EDF on Uniform Multiprocessors,” 2017 IEEE Real-Time Systems Symposium (RTSS), 2017, pp. 319-330, doi: 10.1109/RTSS.2017.00037.↩
-
Valente, P. Using a lag-balance property to tighten tardiness bounds for global EDF. Real-Time Syst 52, 486–561 (2016), doi:10.1007/s11241-015-9237-9↩
-
関連記事 LWN.net 2020/05/22, The deadline scheduler and CPU idle states↩
-
S. Funk, J. Goossens and S. Baruah, “On-line scheduling on uniform multiprocessors,” Proceedings 22nd IEEE Real-Time Systems Symposium (RTSS 2001) (Cat. No.01PR1420), 2001, pp. 183-192, doi: 10.1109/REAL.2001.990609.↩
-
Faggioli, D., Lipari, G. & Cucinotta, T. Analysis and implementation of the multiprocessor bandwidth inheritance protocol. Real-Time Syst 48, 789–825 (2012), doi: 10.1007/s11241-012-9162-0↩
-
Unr-EDF を Linux のタスクスケジューリングに実装するとしたら、最近だと ghOSt (ghost-kernel + ghost-userspace) といった実用的な機構を使う事も考えられるかもしれません。特に、ユーザ空間で、1本の原則ビジーな global scheduling を司るスレッドを動かし、そこで IAP の処理を逐次実行し、userspace からスケジュールさせるというアプローチは、うまくフィットするように思えます。但し、今回は手っ取り早く実装したかったので、直接 kernel に手を入れました。↩
-
タスクセットの feasibility チェックも兼ねています。具体的には、S. Baruah, “Feasibility analysis of preemptive real-time systems upon heterogeneous multiprocessor platforms,” 25th IEEE International Real-Time Systems Symposium, 2004, pp. 37-46, doi: 10.1109/REAL.2004.20. の LP-Feas を指しています。↩
-
P. Wang, Y. Gningue, and H. Zhu, “Improved Algorithm for the Incremental Assignment Problem,” EPiC Series in Computing, vol. 75, 2021, pp. 98-107.↩
-
mode=1 でカジュアルに
を
に置き換えると、オリジナルの証明の拠り所である
をキープする為に
は
とし、最終的に導出される tardiness は 1.5 倍にしておけば良いかなと思ったものの深追いはしていません。直感的に、複数タスクのジョブ群がリリースされた直後も、EDF な割当てを実現した方が性能向上出来るのではないかと考えた為に、試してみたという程度の話です。↩
-
Lee, J., Easwaran, A. & Shin, I. Laxity dynamics and LLF schedulability analysis on multiprocessor platforms. Real-Time Syst 48, 716–749 (2012), doi: 10.1007/s11241-012-9157-x↩
-
S. Funk, J. Goossens and S. Baruah, “On-line scheduling on uniform multiprocessors,” Proceedings 22nd IEEE Real-Time Systems Symposium (RTSS 2001) (Cat. No.01PR1420), 2001, pp. 183-192, doi: 10.1109/REAL.2001.990609.↩
-
Sergey Voronov and James H. Anderson. AM-Red: An optimal semi-partitioned scheduler assuming arbitrary affinity masks. In Proceedings of the 39th IEEE Real-Time Systems Symposium, pages 408–420, 2018.↩
-
S. Baruah and B. Brandenburg, “Multiprocessor Feasibility Analysis of Recurrent Task Systems with Specified Processor Affinities,” 2013 IEEE 34th Real-Time Systems Symposium, 2013, pp. 160-169, doi: 10.1109/RTSS.2013.24.↩