- はじめに
- GigaIO FabreXオープンアーキテクチャとは
- 従来ソリューションとの違い
- GigaIO製品ロードマップ
- FabreXネットワークの使い方
- FabreXネットワークのケーススタディ
- 「ディスアグリゲーテッドコンピューティング」とは何か?
執筆者:佐藤 友昭(取材協力:株式会社 エルザ ジャパン)
※ 「ディスアグリゲーテッドコンピューティングとは何か?」連載記事一覧はこちら
はじめに
数年前から「メモリセントリックアーキテクチャ」や「ディスアグリゲーテッドコンピューティング」という単語が聞かれるようになった。 これらはどういうものであろうか。 従来アーキテクチャや従来コンピューティングに対してどんなメリットがあるのだろうか。 実現に向けた課題にはどんなものがあるのだろうか。
"FabreX is the only communication technology in the industry today that allows for true memory centric operations of Load and Store between Servers and I/O devices across the fabric."
(https://gigaio.com/wp-content/uploads/2021/02/Architecture-Overview-Technical-Note.pdf からの引用)
今回は、現時点で市場にある「ディスアグリゲーテッドコンピューティング」のソリューションとして、GigaIO社製品を見ながら少し考えてみたい。
GigaIO FabreXオープンアーキテクチャとは
GigaIO社は、Linuxサーバ向けのFabreXと呼ばれるファブリックを構成する以下のコンポーネントを提供している。
- ネットワークアダプタとケーブル
- スイッチ
- リソースサーバボックス
- ソフトウェア
これらを使用すると、以下のことが可能になる。
- Linuxサーバと外部のI/Oリソース(GPU, FPGA, NVMe 等のPCIe接続デバイス)との接続
- Linuxサーバ間のRDMAネットワーク接続
従来ソリューションとの違い
従来ソリューションとして、Linuxサーバ間のRDMAネットワーク接続にはEthernet(RoCE)やInfiniBandがあり、Linuxサーバと外部のI/Oリソースの接続にはPCIe接続の拡張ボックスがある。FabreXは一つでその両方を兼ねる。 Ethernet(RoCE)やInfiniBandと同様に、ToR(リーフ)スイッチの上にDirector(スパイン)スイッチを置くことで複数ラック構成も可能である。 PCIe接続の拡張ボックスが接続するのは原則として1台のLinuxサーバに限られるのに対し、FabreXのリソースサーバボックスはスイッチを介して複数台のLinuxサーバと接続することができる。 その結果、ファブリック内の任意のサーバと任意のI/Oリソース(GPU, FPGA, NVMe 等のPCIe接続デバイス)を必要に応じて接続することができる。
GigaIO製品ロードマップ
現行のFabreXネットワークは、PCIe Gen4プロトコルを用いている。 リソースサーバボックスとしては、GPUやFPGAを搭載するアクセラレータプールアプライアンスとNVMe等を搭載するストレージプールアプライアンスをサポートしている。 CPUエンクロージャやメモリエンクロージャはないので、例えばラック全体を1台のSMPマシンとするような構成は取れない。
次期製品では、PCIe Gen4プロトコルから PCIe Gen5 with CXLに移行し、メモリエンクロージャをサポートするとしている。 CXLは、PCIe Gen5と同様のI / Oセマンティクス(CXL.io)、キャッシングプロトコルセマンティクス(CXL.cache)、メモリアクセスセマンティクス(CXL.mem)の3つのプロトコルセットをサポートする。 CXL.ioとCXL.memによるType3 CXLデバイスとしてメモリエクスパンダが実装でき、プロセッサのないNUMAノードのような見え方でホストメモリを拡張することができる。 CXL2.0ではパーシステントメモリもサポートし、プロトコルで指定範囲のデータが永続化されている(電源断によりデータが失われない)ことを保証することができる。 CXLを使用するFabreXは、当初はラック内のコンシステンシドメイン(データが永続化されていることを保証する範囲)をサポートし、その後、コンシステンシドメインをラック間に拡張するとしている。
CPUエンクロージャについては、将来的に理想的なアーキテクチャとして、挙げられているに留まる。
"The ideal architecture includes the ability to disaggregate and compose servers, or (in the future) CPU modules, with CPUs of various types, with 1st and 2nd tier memory; enclosures of 3rd and 4th tier SCM memory pools; enclosures of accelerators of various types, such as GPUs (JBOGs), FPGAs (JBOFs), and ASICs; and enclosures of fully disaggregated storage devices of various tiers including Optane/3DXP, 3D NAND, hard disk drives, and archive hard disk drives."
FabreXネットワークの使い方
FabreXネットワークは以下のリソースで構成されている。
- サーバ
- I/Oデバイス
- スイッチ
サーバはx86/x64ベースのLinux(RHEL/CentOS/Ubuntu)サーバで、FabreXネットワークアダプタとFabreXサーバソフトウェアがインストールされている。 FabreXネットワークアダプタはPCIeカードでPCIe Gen3製品とPCIe Gen4製品があり、いずれも4個のポートがある。
I/Oデバイスは、GPUやFPGAを搭載するアクセラレータプールアプライアンス(APA)やNVMe等を搭載するストレージプールアプライアンス(SPA)で、PCIe Gen3 製品とPCIe Gen4 製品がある。 APAはアクセラレータを最大16個搭載でき、16個のポートがある。 SPAはNVMe SSDを最大24個搭載でき、16個のポートがある。
スイッチは PCIe Gen3 製品とPCIe Gen4製品があり、いずれも24個のポートがある。
スイッチポートとサーバ、スイッチポートとI/OデバイスをFabreXケーブルで物理的に結線する。 1対のポートを1本のケーブルで接続するとx4 PCIeリンクに対応し、x8 PCIeリンクで接続する場合は2対のポートを2本のケーブルで、x16 PCIeリンクで接続する場合は4対のポートを4本のケーブルで結線する。 サーバに接続されているスイッチポートをUSP(またはhostポート)と呼び、IOデバイスに接続されているスイッチポートをDSPと呼ぶ。
スイッチを操作することでどのサーバをどのI/Oデバイスに接続するかを制御できる。 そのための概念としてスイッチ上に複数のパーティションが存在する。 パーティションには1個のUSP(hostポート)と0個以上のDSPが所属する。 1個のポートを複数のパーティションに所属させることはできない。 同一パーティションに所属するUSP(hostポート)とDSPの間のPCIeリンクはスイッチにより接続された状態になる。 DSPをパーティションに入れる操作をBINDと呼び、DSPをパーティションから外す操作をUNBINDと呼ぶ。 x8 PCIeリンクやx16 PCIeリンクの場合、複数ポート単位でBIND/UNBINDする。
スイッチのBIND/UNBIND操作はイーサネットを介してLinuxホスト上のCLI(fmtool)から実行できる他、スイッチの Redfish APIからも実行できる。 OSSのジョブスケジューラであるSLURMや、SuperMicro社のGUI管理ツール(SuperCloud Composer )はFabreXスイッチのReadfish APIに対応しており、SLURMのジョブ毎のリソース要件定義やSuperCloud Composerの管理画面操作でホストとI/Oデバイスの接続および接続解除をコントロールできる。 ホストとI/Oデバイスを接続したり接続解除した場合は、当該ホストをリブートする必要がある。
複数スイッチ構成とする場合は、Director(スパイン)スイッチのDSPとToR(リーフ)スイッチのUSPを接続する。 このときのスイッチ間接続をCrosslinkと呼ぶ。必要な帯域要件に合わせて1本、2本、4本のFabreXケーブルでスイッチ間をCrosslinkする。 Crosslinkで使用しているDSPはBIND/UNBINDできない。 複数スイッチ構成の場合、各スイッチにユニークな名前を設定した上で、うち1台をマネージャスイッチに設定する必要がある。 CLI(fmtool)やRedfish APIはマネージャスイッチに対してのみ実行できる。
FabreXネットワークの構成は、以下の情報を記述したJSONファイル(host_list.json)をCLI(fmtool)に指定することで行う。
- スイッチ名
- USP(hostポート)に接続されたホスト名
- DSPに接続された各I/Oデバイスのエリアス名
- ゾーン名
ゾーンは、接続可能なサーバとI/Oデバイスの集合で、スイッチ1台構成の場合はFabreXネットワーク全体が1つのゾーンになる。 複数スイッチ構成の場合はFabrexXネットワーク全体を1つのゾーンとすることも複数のゾーンに分けることもできる。
JSONファイル(host_list.json)の例(マニュアルからの抜粋)
$ cat host_list.json
{
"s1p1host": "<HOST1_NAME>",
"s1p5host": "<HOST2_NAME>",
"s1p9dsp": "<SWITCH1_PORT9_NAME>",
"s1p13dsp": "<SWITCH1_PORT13_NAME>",
"s1p17dsp": "<SWITCH1_PORT17_NAME>",
"s1p21dsp": "<SWITCH1_PORT21_NAME>",
"switch1": "<SWITCH1_NAME>",
"zone1": "<ZONE1_NAME>"
}
'<’と'>' で囲った部分がそれぞれの名前。重複しない名前を指定する必要がある。 '{' と'}' で囲った部分がゾーン。複数スイッチ構成で複数ゾーンを指定する場合、ゾーン間で内容に重複がないようにする必要がある。
サーバにGPUを接続する
- サーバとGPUを搭載したアクセラレータプールアプライアンス(APA)をFabreXスイッチに結線する。
- FabreXネットワークを構成する(JSONファイル(host_list.json)を記述し、CLI(fmtool)に指定する)。
- サーバが接続されたUSP(hostポート)のパーティションにアクセラレータプールアプライアンス(APA) が接続されたDSPをBINDする。
- サーバをリブートする。
サーバにFPGAを接続する
- サーバとFPGAを搭載したアクセラレータプールアプライアンス(APA)をFabreXスイッチに結線する。
- FabreXネットワークを構成する(JSONファイル(host_list.json)を記述し、CLI(fmtool)に指定する)。
- サーバが接続されたUSP(hostポート)のパーティションにアクセラレータプールアプライアンス (APA)が接続されたDSPをBINDする。
- サーバをリブートする。
サーバにNVMeを接続する
- サーバとNVMeを搭載したストレージプールアプライアンス(SPA)をFabreXスイッチに結線する。
- FabreXネットワークを構成する(JSONファイル(host_list.json)を記述し、CLI(fmtool)に指定する)。
- サーバが接続されたUSP(hostポート)のパーティションにストレージプールアプライアンス (SPA)が接続されたDSPをBINDする。
- サーバをリブートする。
FabreXネットワークのケーススタディ
FabreXネットワークを使用する効果はどのようなものだろうか。 GigaIO社が公開しているいくつかのケーススタディを見ていきたい。
GPU 事例(GigaIO-SDSC-V6.6-1.pdf の内容から)

SDSC(サンディエゴ・スーパコンピュータ・センター)で、12台のGPU(NVIDIA P100)をInfiniBand接続の4台のサーバに3台ずつ内蔵搭載するのと、12台のGPU(NVIDIA 1080Tis)を2台のアクセラレータプールアプライアンス(APA)に6台ずつ搭載し、1台のサーバにFabreXスイッチを介して接続する場合について同じワークロードを実行したときの性能とスケーラビリティを比較している。
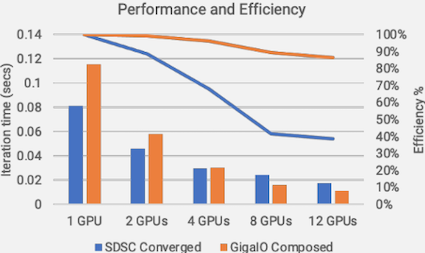
結果は、GPU数が1個、2個ではInfiniBand構成(青)が高速で、GPU4個で両者は並び、GPU8個、12個ではFabreX構成(赤)が高速であったこと、また、GPU12個での論理上限性能に対してInfiniBand構成(青)は39%の性能に対してFabreX構成(赤)は82%の性能が得られたことから、 高価($6,500@)で単体性能で優れるNVIDIA P100を使用するInfiniBand構成よりも、安価($1,000@)で単体性能の劣るNVIDIA 1080Tisを使用するFabreX構成の方がGPU12個での性能とスケーラビリティが優れるとしている。
InfiniBand構成のスケーラビリティが劣った要因としては、異なるサーバに配置されたGPU間で通信する必要がある点を挙げている。 つまり、InfiniBand構成であっても1台のサーバにGPU12台を搭載できれば上記とは違う結果になったものと思われる。 よって、1台のサーバに多数のGPUを接続できる点においてFabreXネットワークを導入する効果が得られたものと考えられる。
1台のサーバに多数のGPUを接続できるメリットについては1台のサーバに32台のGPUをFabreXネットワークを介して接続した環境でのML/DLイメージ処理アプリ(ResNet-50)のスケーラビリティに関するケーススタディ(GigaIO_32GPU_Scaling.V2.0.pdf)も公開されている。 こちらの結果では、論理上限性能に対してGPU16台で78%、GPU32台で63%の効率が得られたとしている。
FPGA事例(GigaIO-Xilinx-New-V4.0.pdfの内容から)

FPGAカード(Xilinx Alveo U250)を1台のサーバに内蔵搭載するのと、1台のアクセラレータプールアプライアンス(APA)に搭載し、1台のサーバにFabreXスイッチを介して接続する場合について同じワークロード(GoogLeNet V1, a 22-layer deep convolutional neural network)を実行したときの性能を比較している。
結果は、サーバ内蔵時の 4,127 イメージ/秒に足してFabreX接続は 4,335 イメージ/秒と、同等の結果が得られたとしている。
FPGAカードをサーバに内蔵搭載した場合、原則として当該サーバ以外からはFPGAカードを使用することができないが、FabreXネットワークを導入することで、複数台のサーバから(現状はサーバのリブートが必要であるものの)FPGAカードを共有することが可能となる。 このときFPGAカードをサーバに内蔵搭載した場合と同じ性能が得られることが確認されたものと考えられる。
上述のGPUのケーススタディのように、1台のサーバに多数のFPGAを接続できることでのメリットはないのだろうか。 また、複数台のサーバ間での真のFPGA共有とは別に、将来のFabreXがメモリエンクロージャ(JBOM)をサポートした際には、ホスト間でJBOM上のメモリを共有し、APA上のFPGAから共有メモリ上のデータを処理するようなユースケースは考えられないだろうか。
NVMe 事例(GigaIO-Intel-Optane-New.V4.0.pdf の内容から)
Intel Optaneドライブを1台のサーバ(A)に内蔵搭載するのと、1台のアクセラレータプールアプライアンス(APA)に搭載し、1台のサーバ(B)にFabreXスイッチを介して接続するのと、当該サーバ(B)にNVMe-oFターゲットを置き、NVMe-oFイニシエーターの別のサーバ(C)から再びFabreXスイッチを介して接続するときのIOPS、バンド幅、レイテンシを比較している。
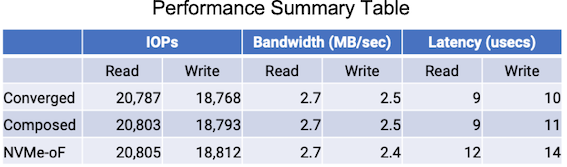
(表中のBandwidth(MB/sec) はBandwidth(GB/sec)の誤りと思われる)
結果は、IOPSとバンド幅は(A)(B)(C)の3者ほぼ同じ。レイテンシは(A)(B)はほぼ同じで、NVMe-oFを余分に介したサーバ(C)が若干劣るとしている。 ストレージに関しては、従来からサーバ内蔵以外にInfiniBandやEthernet(RoCE)接続のNVMe-oFターゲットのソリューションが存在する。 FabreX接続のOptaneドライブ性能はローカル性能同等であり、そういった専用アプライアンスと比べても優れたレイテンシ性能が期待できると考えられる。
「ディスアグリゲーテッドコンピューティング」とは何か?
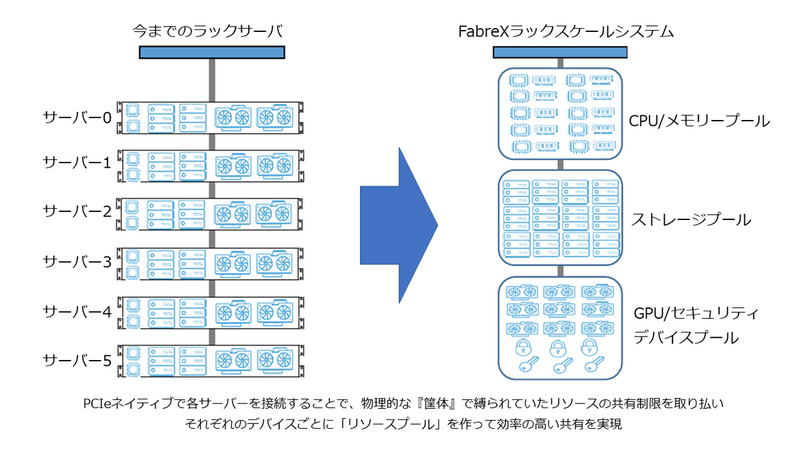
(https://www.elsa-jp.co.jp/products/detail/fabrex-switch/ からの抜粋)
上記の図は、我が国でGigaIO製品を販売しているELSAジャパン社のFabreXスイッチ製品ページからの抜粋であるが、ディスアグリゲーテッドコンピューティングの概念の1つの側面を端的に表現していると思われる。
上述のとおり、現状のFabreXネットワークでは図中の「CPU/メモリープール」に該当する製品は未リリースであるが、ここではそれがあるものとして、この図から冒頭の問いについて考えてみたい。
サーバ仮想化およびHCIとの比較
図の左側は、コンバージドインフラストラクチャ(HCI)のソリューションに多く見られる構成と思われる。 すなわち、2U程度のサーバが複数台描かれており、各サーバにCPU/メモリ/ストレージ/アクセラレータが均等に搭載されている状況を表している。 従来のサーバ仮想化環境では、仮想化プラットフォームが動作する計算ノード群と、計算ノード群に対してデータを供給するストレージノード群に分ける構成方法が一般的であったが、HCIは、計算ノードとストレージノードを統合することで、特に将来のシステム拡張作業を容易にしている。 サーバ仮想化環境では、ノード群にあるコンピューティングリソース(CPU/メモリ/ストレージ/ネットワーク)をプールし、ワークロードに応じて任意のスペックの仮想マシンに構成したり、また、不要になった仮想マシンを解体してコンピューティングリソースをプールに戻したりすることができる。
ここでは以下の制約があると思われる。
- 仮想マシンのスペックは物理ノードのスペックを超えられない
よって、仮想マシンのスペック要件以上の物理ノードを用意する必要があり、将来の要件変化への対応が困難な場合がある。
これに対し、図の右側のディスアグリゲーテッドコンピューティング環境では物理ノードのスペックを要件に合わせて構成することができる。リソースが足りない場合は単純に追加することで対応できる。
シングルシステムイメージとの比較
性能要件に対して並列計算システムを前提にソフトウェアを設計し、スケーラビリティを確保することは従来のHPCシステムでは一般的であるが、AIやビックデータなどユースケースの広がりと、GPUやFPGAなどのアクセラレータ利用機会の増加により、高並列システムではなく高性能な汎用システムが求められるようになってきている。 また、アプリケーションによっては並列化による高速化が困難な場合があり、図の左側のような多台数のクラスタシステムよりも、1台の大規模なSMPシステムの方が性能が得られやすい場合がある。
従来から、このような用途に対して、一般的ではないものの、シングルシステムイメージの取り組みが存在する。 すなわち、図の左側のような複数のシステムを、ソフトウェアで1つのSMPシステムとする取り組みである。
ここでは以下の課題があると思われる。
- ノード内部のインタコネクト性能とノード間のインタコネクト性能のギャップ
つまり、シングルシステムイメージにおけるスケーラビリティ性能は、ノード間のネットワーク性能に依存する。
これに対し、図の右側のディスアグリゲーテッドコンピューティング環境ではソフトウェアではなくハードウェアのレベルで1つのSMPシステムとすることができる(べきである)が、それにはノード内、ラック内、ラック間において十分な性能のインタコネクトが必要となる。 シリコンフォトニクスベースの高速なインタコネクト技術の登場が期待される。
ディスアグリゲーテッドコンピューティング環境としてのFabreXネットワーク
FabreXネットワークでは、PCIeプロトコルを使用しNon-Tranparent Bridgeを介した転送により、ノード間においてもノード内と同等のレイテンシ性能とバンド幅性能を実現している。 次期FabreX製品はPCIe Gen4プロトコルから PCIe Gen5 with CXLに移行し、メモリエンクロージャをサポートするとしている。 2020年の4月に CXL コンソーシアムと Gen-Z コンソーシアムの MOU 合意が発表されている。 MOU 合意の内容の1つとして、CXLプロトコル(ノード内)とGen-Zプロトコル(ラック内およびラック間)間のブリッジングの定義が挙げられている。 将来FabreX製品がGen-Zプロトコルを使用するようになるかどうかについての情報はない。 ディスアグリゲーテッドコンピューティング環境を実現するのに必要な最後のピースである、CPUエンクロージャについては、将来的に理想的なアーキテクチャとして、挙げられているに留まる。
ソフトウェアの課題(感想)
FabreXネットワークを使用することで、任意のサーバにGPU、FPGAなどのアクセラレータや Optane SSD、U.2 SSDなどのストレージを接続でき、かつ、ローカル接続と同等の性能が得られることが分かった。 同時に、サーバ間のRDMA通信も可能であり、x16 PCIe Gen4リンクで接続した場合のカタログ帯域性能は 256Gbit/sec と、 InfiniBand HDRの 200Gbit/sec を超える。
「メモリセントリックアーキテクチャ」や「ディスアグリゲーテッドコンピューティング」の完成に向けた課題には以下などがあると思われる。
- GPU, FPGA, Optane SSD, U.2 SSDなどのホットプラグ機能(OSサポート)
- メモリエンクロージャ(ハードウェア)とメモリホットプラグ機能(OSサポート)
- CPUエンクロージャ(ハードウェア)とCPUホットプラグ機能(OSサーポート)
- メモリセントリックアーキテクチャ対応アプリケーション
上記1,2,3 は主にリブート不要とする仕組みである。上記4はシステム要件を考える上で必要と思われる。 おそらく他にも多数の課題があるものと思われる。 例えば、従来メモリはノードのリブートによってデータが消えることが前提だが、メモリセントリックアーキテクチャにおいて、メモリエンクロージャ上のメモリはCPUやアクセラレータ間のデータ受け渡し場所であり、共有ストレージとしての側面がある。 よって、アプリケーションからは不揮発性であることが前提となると思われる。