「Linuxカーネル2.6解読室」(以降、旧版)出版後、Linuxには多くの機能が追加され、エンタープライズ領域をはじめとする様々な場所で使われるようになりました。
それに伴いコードが肥大かつ複雑化し、多くのエンジニアにとって解読不能なブラックボックスとなっています。
世界中のトップエンジニア達の傑作であるLinuxカーネルにメスを入れ、ブラックボックスをこじ開けて、時に好奇心の赴くままにカーネルの世界を解読する「新Linuxカーネル解読室」プロジェクト。
執筆者 : 高倉遼
※ 「新Linuxカーネル解読室」連載記事一覧はこちら
1. はじめに
本稿では、Linuxの排他制御の仕組みである読み書きスピンロック(RWロック)とRCUを、実際にLinuxでどう使われているのか確認しながら紹介します。いずれも参照が更新に比べて多いデータ構造に対して使われますが、本稿では具体例としてnetfilterにおける排他制御を取り挙げます。
1.1. RWロックとRCUのおさらい
本稿は当初解読室の排他制御にあたる記事を想定して書いておりましたが、解説における具体例としてnetfilterについて調べているうちに、netfilter自体の処理を主に解説することになってしまいました。排他制御自体についてはまた別途解説させていただくため、ここでは簡単に本稿で取り挙げる排他制御を確認します。なおシーケンスカウンタ(seqカウンタ)については、本稿で紹介するnetfilterの排他制御で使用されているため簡単に紹介しています。
通常のスピンロック
ロック変数を用いて実現されており、複数のCPUから同時に一つのデータに対して操作が行われることを防ぎます。ロック変数は、参照・更新処理を区別せず、ロックが取得できるかどうかの判定をするために用いられます。そのため、参照処理同士・更新処理同士・参照と更新処理間のいずれの処理も排他的に実行されます。RWロック
参照処理については同時に実行されることが許可されたスピンロックとなります。更新処理同士・参照と更新処理間については、通常のスピンロック同様に排他的に実行されます。
参照処理同士が同時にロックを取得する場合には、ロック変数は参照数を更新するカウンタとして使用されます。参照と更新処理間の排他では、ロック変数に基づき参照中のCPUがいなくなる状態まで更新処理は行われません。seqカウンタ
RWロックと同様に、参照処理同士については同時に実行され、参照と更新処理・更新処理同士が排他的に実行されます。
RWロックと異なる点として、参照と更新処理間の排他を実現する方法が挙げられます。seqカウンタにおける参照と更新処理間の排他では、参照処理によって更新処理が中断されることはなく、代わりに参照処理は更新処理の終了をカウンタに基づいて待ち合わせます。カウンタは更新処理の開始と終了時に1ずつ加算され、参照開始時にカウンタが奇数もしくは参照開始時と終了時のカウンタの値が異なる場合に待ち合わせが発生します。RCU
参照処理同士に加えて、参照と更新処理についても同時に実行されます。更新処理同士については排他的に実行する必要があります。
RCUではロックを用いた排他制御は行われません。RCUでは更新後のデータと更新前のデータを交換します。データ参照中に更新が行われた場合には、参照処理は更新前のデータを基に行われます。更新前のデータは、参照処理が全てのCPUで終了した後で解放されます。
以下は、それぞれの排他制御の仕組みにおいて、同時実行が許可されている処理 (○) と禁止されている処理(×) を一覧にしたものです。
| 通常のスピンロック | 読み書きスピンロック | seqカウンタ | RCU | |
|---|---|---|---|---|
| 参照と参照 | × | ○ | ○ | ○ |
| 参照と更新 | × | × | × | ○ |
| 更新と更新 | × | × | × | × |
2. netfilterについて
netfilterは、iptablesやnftablesなどで指定される処理を実行するためにLinuxのネットワークスタックに組み込まれている仕組みとなります。iptablesやnftablesでは特定のパケットに対して指定する処理を行うために、そのパケットの条件や処理の内容をルールとして登録します。ルールは、ユーザーによって追加・更新されたり、パケットを送受信した場合には参照の対象になります。3章では、このようなルールに対する参照・更新処理を例にRWロックとRCUを紹介します。
2.1. netfilterのデータ構造・実装
ルールに対する排他制御について触れる前に、netfilterではどのようにルールが登録され、登録したルールに基づきパケットの送受信の際にフィルタリングが行われているのかを、以下のルールを登録した場合を例に確認します。
$ iptables -t filter -A INPUT -s 192.168.x.x -j DROP
iptablesやnftablesではパケットのフィルタリングを行いたいポイント(チェイン)やipアドレスを指定してルールを追加できますが、追加されたルールはnetfilterにおいてテーブルに登録される形で管理されています。テーブルはxt_table構造体で管理され、テーブル名や対象となるプロトコルといったテーブルごとの情報を保持しています。
(include/linux/netfilter/x_tables.h)
222 /* Furniture shopping... */ 223 struct xt_table { 224 struct list_head list; 225 226 /* What hooks you will enter on */ 227 unsigned int valid_hooks; 228 229 /* Man behind the curtain... */ 230 struct xt_table_info *private; 231 232 /* hook ops that register the table with the netfilter core */ 233 struct nf_hook_ops *ops; 234 235 /* Set this to THIS_MODULE if you are a module, otherwise NULL */ 236 struct module *me; 237 238 u_int8_t af; /* address/protocol family */ 239 int priority; /* hook order */ 240 241 /* A unique name... */ 242 const char name[XT_TABLE_MAXNAMELEN]; 243 };
例に挙げたルールが登録されるfilterテーブルの場合には以下のように定義されています。テーブルに登録されているルールの実体は、xt_table構造体のメンバであるxt_table_info構造体で管理されており、ルールの参照や更新はstruct xt_table_info *privateに対する操作となります。そのため、ルールの参照や更新に伴う排他制御はテーブルごとに行われます。
(net/ipv4/netfilter/iptable_filter.c)
23 static const struct xt_table packet_filter = { 24 .name = "filter", 25 .valid_hooks = FILTER_VALID_HOOKS, 26 .me = THIS_MODULE, 27 .af = NFPROTO_IPV4, 28 .priority = NF_IP_PRI_FILTER, 29 };
なお本稿で紹介するロックは参照が主となるデータ構造に対して使われます。例に挙げたコマンドを実行した場合にはテーブルに対する更新処理となりますが、テーブルに対する参照はパケットの送受信に伴い行われるフィルタリングなどの処理で発生します。そのため、本稿で紹介するロックがテーブルを保護するために使われる理由としては、パケットの送受信のたびに発生する参照処理はユーザーによる更新処理に比べて多くなるという想定があることが挙げられます。
2.2. ルールの参照
iptablesやnftablesでは、ルールを登録する際に、パケット送受信の経路上にあるポイントを指定します。これらのポイントはnetfilterによってあらかじめ用意されており、登録されたルールは指定したポイントに対応する関数で適用されます。例に挙げたルールの場合、ipレイヤの受信経路の途中にあるip_local_deliver()となります。
netfilterでは、NF_HOOKマクロにプロトコルやパケットを取得したポイントを引数として渡すことで、フィルタリング等の実際のパケット処理はそれらに紐づく関数によって行われます。ip_local_deliver()の場合、処理の対象となるパケットのプロトコルであるipv4(NFPROTO_IPV4)とパケットを受信経路で取得したことを示すNF_INET_LOCAL_INをNF_HOOKマクロに渡すことで、実際のパケット処理はそれらに紐づくipt_do_table()によって行われます。実際にルールの参照が発生するのもipt_do_table()となります。
239 /* 240 * Deliver IP Packets to the higher protocol layers. 241 */ 242 int ip_local_deliver(struct sk_buff *skb) 243 { 244 /* 245 * Reassemble IP fragments. 246 */ 247 struct net *net = dev_net(skb->dev); 248 249 if (ip_is_fragment(ip_hdr(skb))) { 250 if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER)) 251 return 0; 252 } 253 254 return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, 255 net, NULL, skb, skb->dev, NULL, 256 ip_local_deliver_finish); 257 } 258 EXPORT_SYMBOL(ip_local_deliver);
ipt_do_table()では、引数として渡されるテーブルに登録されているルールを基にパケットのフィルタリング処理を行います。例に挙げたルールの場合にはfilterテーブルに登録されています。フィルタリング処理は、テーブルに処理の対象であるパケットに該当するルールがあるかどうか確認する形で行われ、ある場合には該当したルールに基づきパケットは処理されます。そのため、ipt_do_table()における参照区間は、テーブルの参照が開始されるL.260からテーブルに登録されているルールの必要な確認を終えたL.354までとなります。
(net/ipv4/netfilter/ip_tables.c)
221 /* Returns one of the generic firewall policies, like NF_ACCEPT. */ 222 unsigned int 223 ipt_do_table(void *priv, 224 struct sk_buff *skb, 225 const struct nf_hook_state *state) 226 { ... 237 const struct xt_table_info *private; ... 258 local_bh_disable(); 259 addend = xt_write_recseq_begin(); 260 private = READ_ONCE(table->private); /* Address dependency. */ 261 cpu = smp_processor_id(); 262 table_base = private->entries; 263 jumpstack = (struct ipt_entry **)private->jumpstack[cpu]; ... 275 e = get_entry(table_base, private->hook_entry[hook]); 276 277 do { // フィルタリング処理 ... 354 } while (!acpar.hotdrop); 355 356 xt_write_recseq_end(addend); 357 local_bh_enable(); 358 359 if (acpar.hotdrop) 360 return NF_DROP; 361 else return verdict; 362 }
なおルールの参照処理においては、ルールごとに保持している統計情報(pkts、byte)に対しても排他制御が行われています。統計情報は、パケットの送受信においてルールが参照されるたびに更新されます。
排他制御はseqカウンタによって行われ、次節で後述する排他制御はルールの参照区間が統計情報の更新区間であることを利用しています。ルールの参照区間がxt_write_recseq_begin/end() という更新区間用の関数で開始・終了しているのはそのためです。
$ iptables -v -L INPUT
Chain INPUT (policy ACCEPT 178 packets, 12312 bytes)
pkts bytes target prot opt in out source destination
0 0 DROP all -- any any 192.168.105.9 anywhere
2.3. ルールの追加・更新
ルールの参照処理と同様に、ルールの追加などの更新処理もテーブルに対する処理となります。そのため、ipt_do_table()などのパケットの送受信において発生するルールの参照処理との間では排他制御が必要となります。例に挙げているルールの場合、パケットの受信に伴い発生するfilterテーブルへの参照処理と、filterテーブルにルールを追加する更新処理となります。
netfilterでは、テーブルの更新はプロトコル共通の処理としてxt_replace_table()で行われています。xt_replace_table()は、引数として追加されるルールが登録されているテーブル(struct xt_table_info *newinfo)のポインタを受け取り、更新対象のテーブル(table->private)を置き換えます。そのため更新区間は、旧テーブルを取得してから新テーブルへの置き換えが完了するまでのL.1401からL.1421までとなります。旧テーブルについては、xt_replace_table()の戻り値として呼び出し元にて削除されます。
なお、現在の実装では、更新処理を行っているコアを除いて更新中もパケットの送受信を禁止していない(L.1400)ため、更新が行われているテーブルの参照は更新処理中も発生します。更新区間の直後に行っている待ち合わせ(L.1430-L.1440)は、更新後にまだ更新前のテーブルを参照しているCPUがいた場合に、更新前のテーブルの削除が参照中に行われることを防ぐ目的で行われています。待ち合わせはseqカウンタを用いたnetfilter独自の仕組みで行っており、CPUごとのカウンタ変数(u32 seq)が参照区間中(xt_write_recseq_begin~xt_write_recseq_end())にいる場合には奇数、いない場合には偶数となっていることを利用して、すべてのCPUで参照が終了する(カウンタ変数の最下位ビットが0)まで待ち合わせを行っています。
1383 struct xt_table_info * 1384 xt_replace_table(struct xt_table *table, 1385 unsigned int num_counters, 1386 struct xt_table_info *newinfo, 1387 int *error) 1388 { 1389 struct xt_table_info *private; ... 1399 /* Do the substitution. */ 1400 local_bh_disable(); 1401 private = table->private; ... 1412 newinfo->initial_entries = private->initial_entries; 1413 /* 1414 * Ensure contents of newinfo are visible before assigning to 1415 * private. 1416 */ 1417 smp_wmb(); 1418 table->private = newinfo; 1419 1420 /* make sure all cpus see new ->private value */ 1421 smp_mb(); 1422 1423 /* 1424 * Even though table entries have now been swapped, other CPU's 1425 * may still be using the old entries... 1426 */ 1427 local_bh_enable(); 1428 1429 /* ... so wait for even xt_recseq on all cpus */ 1430 for_each_possible_cpu(cpu) { 1431 seqcount_t *s = &per_cpu(xt_recseq, cpu); 1432 u32 seq = raw_read_seqcount(s); 1433 1434 if (seq & 1) { 1435 do { 1436 cond_resched(); 1437 cpu_relax(); 1438 } while (seq == raw_read_seqcount(s)); 1439 } 1440 } 1441 1442 audit_log_nfcfg(table->name, table->af, private->number, 1443 !private->number ? AUDIT_XT_OP_REGISTER : 1444 AUDIT_XT_OP_REPLACE, 1445 GFP_KERNEL); 1446 return private; 1447 } 1448 EXPORT_SYMBOL_GPL(xt_replace_table);
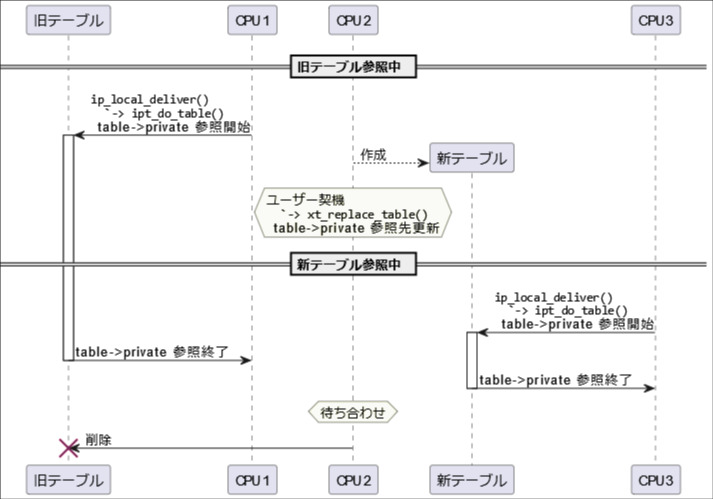
以下の図では、CPU2における更新処理前後で参照先となるテーブルを表した図です。CPU1が更新処理開始前、CPU3が更新処理開始後にテーブルの参照をそれぞれ開始しています。
3. RWロック・RCUの比較
本章では、2章で紹介したnetfilterにおける参照・更新区間を、RWロック・RCUで保護した場合の実装例とそれぞれのロックの特徴について確認します。netfilterでは過去にそれぞれのロックを使った実装がされています。それぞれのロックが採用されるに至った経緯は面白いので、ぜひ興味のある方は実際のコミット 784544739a25 ("netfilter: iptables: lock free counters") も参照してみてください。
3.1. RWロックで保護した場合
2章でも確認したとおり、ルールはipt_do_table()において参照される際もxt_replace_table()において更新される際もテーブル単位での処理となります。まず、それら参照・更新が行われる区間においてテーブルを保護するために、RWロック変数(struct rwlock_t)をテーブルごとに確保します。RWロック変数の初期化はrwlock_init()で行います。
xt_register_table()は、xt_replace_table()と同様に、netfilterがプロトコル共通で用意しているテーブル初期化を行う関数となります。
diff --git a/include/linux/netfilter/x_tables.h b/include/linux/netfilter/x_tables.h index 5897f3dba..e93cbd2f4 100644 --- a/include/linux/netfilter/x_tables.h +++ b/include/linux/netfilter/x_tables.h @@ -226,6 +226,8 @@ struct xt_table { /* What hooks you will enter on */ unsigned int valid_hooks; + rwlock_t lock; + /* Man behind the curtain... */ struct xt_table_info *private; diff --git a/net/netfilter/x_tables.c b/net/netfilter/x_tables.c index 21624d683..65f8ebe33 100644 --- a/net/netfilter/x_tables.c +++ b/net/netfilter/x_tables.c @@ -1476,6 +1459,8 @@ struct xt_table *xt_register_table(struct net *net, /* Simplifies replace_table code. */ table->private = bootstrap; + rwlock_init(&input_table->lock); + if (!xt_replace_table(table, 0, newinfo, &ret)) goto unlock;
3.1.1. 競合区間の保護
RWロックの特徴として、現在のseqカウンタを用いた排他制御と同様に、参照区間については複数のCPUが同時に実行できる点が挙げられます。パケット送受信のように頻繁に複数のCPUで同時に行われる処理においてRWロックを用いることで、通常のspinロックで発生するようなお互いの参照処理を待ち合わせることによるオーバーヘッドをなくすことができます。
参照処理(read_lock_bh()~read_unlock_bh())と更新処理(write_lock_bh()~write_unlock_bh())が競合した場合には、それぞれの実行は排他的に行われます。そのため、更新処理後に発生する参照処理は常に最新のデータに対して行われることから、現在のseqカウンタを用いた実装のように待ち合わせを行う必要はありません。しかし、いつでも発生し得るパケットに対して常に最新のルールが適用されている必要はなく、RWロックを用いた場合に発生する更新処理による参照処理の中断は不要なオーバーヘッドとなります。
diff --git a/net/ipv4/netfilter/ip_tables.c b/net/ipv4/netfilter/ip_tables.c index 7da1df499..fe9594933 100644 --- a/net/ipv4/netfilter/ip_tables.c +++ b/net/ipv4/netfilter/ip_tables.c @@ -255,9 +255,8 @@ ipt_do_table(void *priv, acpar.state = state; WARN_ON(!(table->valid_hooks & (1 << hook))); - local_bh_disable(); - addend = xt_write_recseq_begin(); - private = READ_ONCE(table->private); /* Address dependency. */ + read_lock_bh(&table->lock); + private = table->private; cpu = smp_processor_id(); table_base = private->entries; jumpstack = (struct ipt_entry **)private->jumpstack[cpu]; @@ -353,8 +352,7 @@ ipt_do_table(void *priv, } } while (!acpar.hotdrop); - xt_write_recseq_end(addend); - local_bh_enable(); + read_unlock_bh(&table->lock); if (acpar.hotdrop) return NF_DROP; diff --git a/net/netfilter/x_tables.c b/net/netfilter/x_tables.c index 21624d683..65f8ebe33 100644 --- a/net/netfilter/x_tables.c +++ b/net/netfilter/x_tables.c @@ -1397,14 +1397,14 @@ xt_replace_table(struct xt_table *table, } /* Do the substitution. */ - local_bh_disable(); + write_lock_bh(&table->lock); private = table->private; /* Check inside lock: is the old number correct? */ if (num_counters != private->number) { pr_debug("num_counters != table->private->number (%u/%u)\n", num_counters, private->number); - local_bh_enable(); + write_unlock_bh(&table->lock); *error = -EAGAIN; return NULL; } @@ -1420,24 +1420,7 @@ xt_replace_table(struct xt_table *table, /* make sure all cpus see new ->private value */ smp_mb(); - /* - * Even though table entries have now been swapped, other CPU's - * may still be using the old entries... - */ - local_bh_enable(); - - /* ... so wait for even xt_recseq on all cpus */ - for_each_possible_cpu(cpu) { - seqcount_t *s = &per_cpu(xt_recseq, cpu); - u32 seq = raw_read_seqcount(s); - - if (seq & 1) { - do { - cond_resched(); - cpu_relax(); - } while (seq == raw_read_seqcount(s)); - } - } + write_unlock_bh(&table->lock); audit_log_nfcfg(table->name, table->af, private->number, !private->number ? AUDIT_XT_OP_REGISTER :
3.2. RCUで保護した場合
RCUでは、2章で紹介したnetfilter独自のseqカウンタと同じく待ち合わせによって参照と更新処理の排他制御が行われます。そのため、RWロックのように更新処理中でも参照処理は中断されません。
現在のseqカウンタを用いた待ち合わせ実装では、ルールの更新処理中にパケットの送受信が行われた場合でも参照処理はブロックされずに更新前のルールを基に行われるため、更新処理は更新前のルールの参照がすべてのCPUで終了することを待ち合わせていることを紹介しました。同様の排他制御をRCUでは、参照区間の開始と終了を設定するために用いるrcu_read_lock()/rcu_read_unlock()と更新用APIを用いて実現します*1。更新用APIは、用途に応じて様々用意されています。
| 関数名 | 説明 |
|---|---|
| synchronize_rcu() | この関数呼び出し前に開始されたすべてのRCU参照区間の終了を待ち合わせる。 |
| synchronize_rcu_expedited() | 同上。IPIを用いてRCU参照区間を終了させるため、待ち合わせの完了がsynchronize_rcu()に比べて早くなる。 |
| call_rcu() | 指定したコールバックをRCU参照区間の待ち合わせ完了後に呼び出す。 |
| kfree_rcu() | 指定したオブジェクトをRCU参照区間の待ち合わせ完了後に削除する。 |
以下の実装の場合には、synchronize_rcu()を用いることで、現在のseqカウンタを利用した待ち合わせと同様の待ち合わせを実現しています。
diff --git a/net/ipv4/netfilter/ip_tables.c b/net/ipv4/netfilter/ip_tables.c index 7da1df499..b0394a6cf 100644 --- a/net/ipv4/netfilter/ip_tables.c +++ b/net/ipv4/netfilter/ip_tables.c @@ -255,9 +255,8 @@ ipt_do_table(void *priv, acpar.state = state; WARN_ON(!(table->valid_hooks & (1 << hook))); - local_bh_disable(); - addend = xt_write_recseq_begin(); - private = READ_ONCE(table->private); /* Address dependency. */ + rcu_read_lock_bh(); + private = rcu_dereference(table->private); cpu = smp_processor_id(); table_base = private->entries; jumpstack = (struct ipt_entry **)private->jumpstack[cpu]; @@ -353,8 +352,7 @@ ipt_do_table(void *priv, } } while (!acpar.hotdrop); - xt_write_recseq_end(addend); - local_bh_enable(); + rcu_read_unlock_bh(); if (acpar.hotdrop) return NF_DROP; diff --git a/net/netfilter/x_tables.c b/net/netfilter/x_tables.c index 21624d683..ea3baf5c6 100644 --- a/net/netfilter/x_tables.c +++ b/net/netfilter/x_tables.c @@ -1397,47 +1397,23 @@ xt_replace_table(struct xt_table *table, } /* Do the substitution. */ - local_bh_disable(); + mutex_lock(&table->lock); private = table->private; /* Check inside lock: is the old number correct? */ if (num_counters != private->number) { pr_debug("num_counters != table->private->number (%u/%u)\n", num_counters, private->number); - local_bh_enable(); + mutex_unlock(&table->lock); *error = -EAGAIN; return NULL; } newinfo->initial_entries = private->initial_entries; - /* - * Ensure contents of newinfo are visible before assigning to - * private. - */ - smp_wmb(); - table->private = newinfo; - - /* make sure all cpus see new ->private value */ - smp_mb(); - - /* - * Even though table entries have now been swapped, other CPU's - * may still be using the old entries... - */ - local_bh_enable(); + rcu_assign_pointer(table->private, newinfo); + mutex_unlock(&table->lock); - /* ... so wait for even xt_recseq on all cpus */ - for_each_possible_cpu(cpu) { - seqcount_t *s = &per_cpu(xt_recseq, cpu); - u32 seq = raw_read_seqcount(s); - - if (seq & 1) { - do { - cond_resched(); - cpu_relax(); - } while (seq == raw_read_seqcount(s)); - } - } + synchronize_rcu(); audit_log_nfcfg(table->name, table->af, private->number, !private->number ? AUDIT_XT_OP_REGISTER :
なお現在のnetfilterでは、RCUは使わずにあえて独自の待ち合わせ実装を行っています。実際に、現在のseqカウンタを用いたnetfilter独自の実装に至るまでに、これまでRCUによる実装が2度取り込まれました。しかし、取り込まれたいずれのRCUによる実装も、更新処理にかかる時間が大幅に増えたことが問題となり*2、その後リバートされています。原因はRCUの待ち合わせに伴うオーバーヘッドですが、現在のnetfilterが独自のseqカウンタによる待ち合わせを実装している背景として、この更新処理におけるオーバーヘッドを改善するためという点が挙げられます。
3.3. 更新処理におけるオーバーヘッド(余談)
最後に、先述したRCUを使用した場合に発生する更新処理のオーバーヘッドがどの程度になるのかについて少し触れたいと思います。コミット 942e4a2bd680 ("netfilter: revised locking for x_tables")のやり取りには、200ルール追加するという処理をRWロック(v2.6.29)では0.2秒で終えていたにも関わらず、RCUの実装後(v2.6.30-rc1)には6秒かかるようになったとあります*3。
Adding 200 records in iptables took 6.0sec in 2.6.30-rc1 compared to 0.2sec in 2.6.29.
以下は現在のnetfilter(v6.11カーネル)の更新処理を、RCU(synchronize_rcu())で保護してみた場合にかかった時間(ms)です。synchronize_rcu_expedited()を使用した場合は参考までに載せてみました。
| 現在の実装 | synchronize_rcu() | synchronize_rcu_expedited() |
|---|---|---|
| 1109 | 5073 | 1104 |
値は200のルールを追加する以下の処理にかかった時間となります*4。検証にはラズパイ4(4コア)を使用しました。
for i in {1..200}
do
iptables -A INPUT -s 192.168.105.$i -j DROP
done
RCUと現在の実装を比較してみると、更新処理に大きく時間がかかっていることがわかります。この遅延の原因は、synchronize_rcu_expedited()については現在の実装と同様の結果であることからも、待ち合わせであることがわかります。
このRCUにおける更新処理の遅延はnetfilterが独自の排他制御を実装するきっかけとなりましたが、RCUを採用した元々の目的は参照処理の性能向上でした。現在の実装を見るとわかる通り、シーケンスカウンタはCPUごとに用意される実装となっています。これは、グローバルなロックを使用するRWロックの場合において発生する参照処理ごとのキャッシュのフラッシュを回避する目的があります。当初この参照処理の際のキャッシュの問題をRCUを使用することで克服することが試みられましたが、上記の結果の通りRCUには更新処理に大きく時間がかかってしまうという点が問題になりました。
現在のseqカウンタを用いた独自の実装は、このような参照処理と更新処理両方の性能が考慮されて至った実装です。RCUによる実装以降*5のnetfilter独自の排他制御には、現在に至るまでに様々な改良・修正が加えられています。netfilterの排他制御について調べる際には、ぜひ過去に行われてきた修正とその背景にも注目してみてください。
*1:RCUが待ち合わせを実現する仕組み自体の解説は別の記事でしたいと思います。
*2:https://lore.kernel.org/all/Pine.LNX.4.64.0904101656190.2093@boston.corp.fedex.com/
*3:https://lore.kernel.org/all/Pine.LNX.4.64.0904101656190.2093@boston.corp.fedex.com/
*4:https://lore.kernel.org/all/b6a2187b0904101807x77578e0dhd0093d233839ef67@mail.gmail.com/
*5:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=942e4a2bd680c606af0211e64eb216be2e19bf61