- 概要
- ライトニングトーク
- キーノート
- 一般セッション
- Node Resource Management, the Big Picture
- Nurturing Security Permaculture
- On the Hunt for etcd data inconsistencies
- Setting up Etcd with Kubernetes to Host Clusters with Thousands of Nodes
- The State of Green Software & Cloud Native
- Interactive Playground to Learn Kubernetes and Cloud Native Security
- Cloud Native Edge Computing with KubeEdge: Updates and Futuer
- SIG Network: Intro and Updates
- Revampinng Kubernetes with Contextual and Structured Logging
- まとめ
執筆者 : 岩本 俊弘
概要
KubeCon + CloudNativeCon EU が 2023年4月18日から21日の日程で行われた。 18日には co-located event があり、本体のイベントは18日夕方のライトニングトークセッションと19日からの3日間であった。
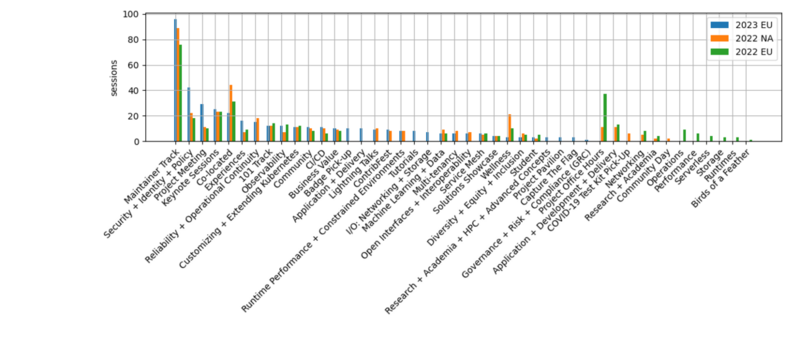
トラック毎のセッション数の比較を下に示す(比較しやすいように一部の分類名は読みかえている)。
セキュリティ関連のセッションが急増しているように見えるが、今回は co-located イベントとしての security day がなかったので、単純に比較はできない。
また、目立たないが、Networking と Storage がまとめて1つの分類になっていて、以前に比べるとセッション数も少なくなっている。
現地参加は10,000人で wait list が2,000人だったそうだ。前年は参加者が7,000人だったのでかなり増えている。 virtual 配信では co-located イベントがほとんど同時中継されず、virtual スポンサーブースもなくなっていたりと、扱いが悪くなっていたのがちょっと気になった。
全ての発表動画は YouTube の CNCF channel (https://www.youtube.com/c/cloudnativefdn) から参照できる。過去のイベントでは質疑応答が削られていたこともあったが、今回はフルに収録されていた。
ライトニングトーク
最初の2つの発表はビデオ録画であった。
Debugging Kubernetes E2E Tests with Delve
delve を使って Kubernetes の e2e test をデバッグする話。 Makefile とか script にそのための仕組みがはいっているらしく、変数やオプションを追加するだけで簡単にできるようになっていた。
GreenCourier
FaaS のエネルギー消費量が多いらしい。GreenCourier というものを作って carbon efficiency score を計算して CO2 発生量の少ない地域のクラスタで workload を実行するという話であった。
Power Aware Scheduling in Kubernetes
電力を oversubscribe してるからうまくやらないとブレーカがおちちゃうという話だった。 会場を背景に selfie 撮ったりして楽しそう。
キーノート
最初に話したのは Priyanka Sharma 氏で、録画での登場であった。妊娠後期で今は飛行機に乗れないとのことであった。 子供にコンピュータを教える取り組みとか、 kind を叩いて Kubernetes 簡単でしょといった話をしていた。
次に CTO の Chris Aniszczyk 氏が出てきて、今回は sold-out で wait list が 2,000人もあったから次はパリでもっと広い会場でやるとか、次は中国で9月にやるといった話をしていた。 組織別の Kubernetes への contribution のグラフを出して、いろんな会社がやるようになったから Google の比率が下がっているといった話もしていた。
CNCF プロジェクトをまとめて紹介するのもいつも通りである。量が多いからか2日に分けて紹介していた。
Dawn Foster 氏は maintainer burnout の話をして contributor を増やすにはどうすればいいかという話をしていて、これも定例の話題であった。 Diversity, Equity, Inclusion もいつもの話題であったが、equity (平等) を示すイラスト (https://interactioninstitute.org/illustrating-equality-vs-equity/) がわかりやすかった。 contribution に参加するにあたってドキュメントが障害になってるので maintainer は週1時間でいいから contributor doc を書いてねと action item を提示していた。
"Inside Envoy" という映画を制作して2日目の夜に公開するから見にきてねという話もあった。 家族にやっている仕事を説明するのが難しいから助かる、みんなもこの映画を友達とかにシェアしてねといった紹介をしていた。 現在 YouTube で視聴できる。
EU cyber resilience Act の問題にも触れられていた。 サイバーセキュリティに関して OSS 開発者が過大な責任を負わされるかもしれないといった話で、 legal stuff を話したくないけど行動に参加してくれみたいなことを言っていた。 この件に関するセッションがあると紹介していたが、配信されていなかった。
キーノートの最後で Emily Fox の co-chair は最後だよと言っていた。泣きそうになってた。
一般セッション
Node Resource Management, the Big Picture
The big picture という題名の通り、ノードリソース管理に関するいくつもの話題を駆け足で説明するセッションで、5人くらい登壇していた。それぞれの話題について必要なら去年の発表などを参照せよといった感じであった。
各種リソースマネージャは長い間 beta のままだったけど、GA にしようという流れになって、Device, CPU, topology manager がそれぞれ 1.26, 1.26, 1.27 で GA になった。 昔の Kubernetes は API Server, Scheduler, Kubelet, CRI Runtime から構成されていたが、今は DRA とか NRT とか topology aware scheduling plugin とかが増えて複雑になっていると図を出して説明していた。
Dynamic Resouce Allocation は古い device plugin API を置き換えるもので、ResourceClaims リソースを使うとか、複数 Pod でデバイスを共有できるようになったりすると説明していた。
NRI は Node Resource Interface の略で、NRI plugin が OCI Spec を書きかえる図を出して、去年の KubeCon の発表があるよとか scheduler extension もあるよと簡単に触れていた。
NodeResourceTopology API は NUMA-aware スケジューリングに関する機能で、1枚のスライドで CRD based だとか、去年の KubeCon EU の topology aware scheduling のプレゼンがあるとか、 NRI plugin と関係しているなどと駆け足で説明していた。
cgroup v2 についても1枚のスライドで、PSI metrics とか memoryQoS が 1.27 で alpha になったとか他にもいろいろやろうとしていると説明していた。 これについては去年のデトロイトでの KubeCon の発表が参考に挙げられていた。
会場には300人くらい観客がいて結構多いと思った。
realtime application 動かしてる人の質問に答えて、 block IO separation は最近の containerd とか cri-o でできるようになってると言っていた。
また、kernel で isolated cpu になってるのを Pod で使うように選べないのかという質問に対しては、Kubernetes 自体でサポートする予定はないが plugin を書けばできるとか言っていた。
Nurturing Security Permaculture
SIG Security がどんなことをやっているかの話であった。 発表者が全員 N95 マスクをしていて、他のセッションでは全くといっていいほどマスク姿を見なかったので不思議である。
最初は documentation の話で、ドキュメントを通して security aware にすることがゴールの1つだそうである。 現在進行中のプロジェクトで hardening guide を作ろうとしているよといった話もあった。
次は third-party security audits の話で、報告書は kubernetes/sig-security repo にあって、public にする前に issue をいくつ直したとか言っていた.
tooling では、CVE feed や CVE scanner といったツールを扱っているそうである。
self assessments というのは自分達でセキュリティがどうなってるか調べるということのようである。 効果として、セキュリティに対する姿勢を改善するとか、security muscle を鍛えるといったことを挙げていた。 vSphere CSI ドライバに対して self assessments をやっていて、data flow diagram が完成したとか、次は STRIDE model とか fuzzing とかをやると話していた。
permaculture とか gardening とか fertilizing とか今回の KubeCon のキーワードを使ってなんか話していたが、この比喩はいまいちよくわからなかった。
SecurityContextDeny を消せないかとか話してる。 内輪での議論で消したほうがよさそうだということになったのでより広いオーディエンスに対して意見を聞いて deprecated にしていきたいとのことである。 どうもこれは1つの例で、SIG security が決定権を行使するわけではなくて、みんなのために意見を聞いて活動しているんだということが言いたかったようである。
On the Hunt for etcd data inconsistencies
etcd の話である。 3年ぶりの minor release である v3.5.0 において、複数の data inconsistency があったそうである。 しかも etcd 自体にはそういった問題を検出する十分なテストがないそうである。 既存のテストとして etcd functional tests や Jepsen があるが、どちらもだめだと言っていた。
どんな条件でも正しく動作するのが robustness だとか、どういう条件でどういう正しさを確認するのかといった話をしたあと、model-based testing でやるのだと言っていた。 etcd を動かした後に、同様の操作を hash map でつくったモデルで動かして結果が一致するかで正しさを検証するそうである。 また、linearizablity は、矛盾なく説明できる動作順序がみつけられるかで判定するそうである。
他に、Kubernetes は etcd の動作について文書化されていないいくつもの仮定を置いて動いていることがわかったので、the implicit kubernetes-etcd contract という文章を書いたという話もしていた。 (参考: https://github.com/etcd-io/etcd/issues/15820)
Setting up Etcd with Kubernetes to Host Clusters with Thousands of Nodes
最初に Kubernetes の HA 構成の図を出して scheduler も controller も active なのは 1 つだけだよとか話してる。 etcd は etcd と etcd events に分けて負荷を若干分散させることはできるようである。
Pod churn を減らせとか configmaps/secrets を immutable にしろとか細かい話になったきた。 1 つの kubectl コマンドの裏で複数の API call が動くこともあるよと説明している。
次に実際に起きた incident (性能問題) についての話になって、負荷のグラフが出てきた。 list API call が重いとのことで、resourceVersion を指定すると cache に対して動作するけど、指定しなければ etcd に対する quorum read になると言っている。
30,000 個くらいの Pod がある環境で list Pod したときの時間を例示していて、確かに resourceVersion の有無で数倍性能が違っている。 labelSelector を指定しても resourceVersion が無ければ結局 full list を etcd から取ってくるとも説明していた。 ちなみにこの環境では Pod listをjsonでとると1GBになるとか言っていた。 負荷が低いので list より informer を使うべきだとも言っていた。
元々の incident の話に戻ると、nodegroup controller という自作のコントローラが原因で、nodegroup delete が対象ノードに属する Pod の list をとるのが悪いということであった。 ノード単位の list pod は結局 etcd から全部とってくることになるので、list API call が結局ノード数回繰り返されるということである。 audit log が分析の役に立ったそうである。
コミュニティでも以下の対策がでていると言っていた。
- streaming lists KEP-3157
- API priority and fairness KEP-1040
以下のような質問がでていた。
- dense nodes だとどうなのという質問。よく分からないみたい。kubelet の問題か。
- etcd はどれくらい scale するのという質問。使い方による。service の負荷が高いよとか言っていた。
- limit はどうなのという質問。2GBがどうこうとか言ってる。datadog で 5000podくらいなら平気だよと言っていた。
The State of Green Software & Cloud Native
TAG Enavironmental Sustainability の人たち (所属は Liquid Reply と Red Hat) の話である。 冒頭でパリ協定がどうこうとか言っていた。
コードを書いてはいないけど活動してるようである。 今は Kubernetes best practices を集めていると言っていた。
survey の応答の内訳は 67% Europe、24% NA、アジアは4%
Cloud Native ENV Landscape では observability の話をしていて、scaphandre と kepler というソフトを紹介し、 Kubernetes の電力消費量を測るとか言っていた。
質問で、green software foundation の話が出た。それは Microsoft がやっていて、communcation channel はあるけど collaborate はしていないと答えていた。
greenwashing をしたい企業が近づいてきたらやっかい (tricky) じゃないのといった質問もあって、ちょっとおもしろかった。
Interactive Playground to Learn Kubernetes and Cloud Native Security
このプレゼンの背景として、なんで Kubernetes security が大事なのかとか、security team が cloud native tools に慣れてないという問題を最初に話していた。
次にプレゼン時間の大半を使って、脆弱な Kubernetes を使って攻撃の手口をいろいろ説明していた。
最後に、これらの攻撃を簡単かつ安全に試せるツールとして kubernetes goat (https://madhuakula.com/kubernetes-goat/) の話になった。 ドキュメントも整備されてるよ、攻撃シナリオもあるよなどと示していた。
Cloud Native Edge Computing with KubeEdge: Updates and Futuer
edge では network も hardware もデータセンターとは違うという背景を説明して、それを解決するために KubeEdge を作っているのだとか、2018 年からやってると説明していた。
自動車の software OTA とか、人工衛星(ネットワークが数秒つながって数秒きれるという特殊な環境)にも適用してると言っていた。
kubeedge architecture の図を映して、websocket で cloud と edge を接続しているなどと特徴を説明していた。 Pod のデプロイの流れ (API server -> CloudCore -> EdgeCore) も説明していた。
次に最近の変更点として、以下のトピックについて説明していた。
- Device Management Interface
- SIG networking: edgemesh
- SIG AI: sedna
- SIG Robotics
- SIG security (SLSA Level4 に対応したとか、 integrated fuzzing をやっているという話)
ケーススタディでは、Low Earth Orbit 衛星の話 (衛星でも Sedna を動かしている) や offshore oilfield でどういう制約があるといった話をしていた。
開発コミュニティの話では、いろんなパートナーがいると紹介していたが、commit は約半数が Huawei のようである。
開発ロードマップを最後に出していた。いろいろやろうとしている。
テストはどうやってるのという質問があって、特別なハードウェアは要らないなどと答えていた。 最終日の午後ともあって会場は閑散としている。(あるいは広い会場だったのかもしれない。)
SIG Network: Intro and Updates
Kubernetes の network の話を駆け足で説明していた。
最初は EndpointSlices の話であった。 元々 Service では Endpoints を Pod に対応づけて使っていたが、Service あたり 1000 Pod という制限があった。 EndpointSlices は sharding することによりよりスケーラブルで、Dual Stack などの機能もサポートできるようになったと説明していた。
次は Ingress の話題で、5年以上あるけど (non-portable extensions やパーミッションモデルなど) いくつか問題がある。 なので、次世代の API として Gateway API を作っていて、去年 beta になった。 今年 (シカゴの前に) GA にしたいと言っていた。
これについてはすこし詳しく説明していて、GatewayClass, Gateway といった非 route リソース と HTTPRoute などの route リソースの2種類に分かれると説明していた。 Ingress より extensible になってるとか、namespace を跨げるようにするため ReferenceGrant リソースがあるといった話もしていた。
GAMMA project にも触れていた。Gateway API for Mesh Management and Administration の略だそうである。 Gateway API をサービスメッシュの east/west traffic に使うそうである。
Gateway API 全般については gateway-api.sigs.k8s.io を見てくれとまとめていた。
Admin Network Policy の話もしていた。 Network Policy と違ってクラスター全体に制限をかけるためのもので、今は alpha だが今年中に beta にしたいと言っていた。
kube-proxy に nftables backend ができるという話もあった。
https://github.com/orgs/kubernetes/projects/10 にKEPの一覧がある。 Topology Aware routing の話もしていた。
会場には意外と人が多かった。
Revampinng Kubernetes with Contextual and Structured Logging
Kubernetes のログを構造化ログに変えたいとのことで、
Kubernetes のログがごちゃごちゃなのをどうにかしたいとか、モニタリングを自動化したいといった動機を最初に話してた。
ログに対する query をやりやすくしたいとか、 klog を置きかえようとはしてないなどど goals/non goalsを説明していた。
また、contextual logging というものは、関数に logr.Logger のインスタンスを渡すようにすることで呼ばれた先の関数のログに key-value ペアを追加できるようにするといったもののようである。
ログメッセージに key-value ペア (pod とか namespace) がいくつかつくというログフォーマットを説明してた。
他にも、 klog に JSON support を足すとか、各コマンドのログは --logging-format オプションで切り換えられるといった細かい話をしていた。
どうやって書き換えるべきかを記述した migration instruction がある。 たくさん書き変えないといけないので手伝ってねとまとめていた。
まとめ
今回は前回までのマスク着用義務もなくなったようであり、オンサイトでの参加者数も順調に回復しているようなので、オンラインとのハイブリッドというよりオンラインが従であるという印象を受けた。 ただ、オンラインでの視聴に特に不都合はなく、最近の動向を短時間でキャッチアップできるという点ではいつも通りであった。
数えてみると Kubernetes と関わるようになってもう6年も経っている。 その間ソフトウェアとして成熟してきたが、上で触れたようにまだ開発は続いており、Kubernetes の適用範囲も(より大規模なものや、エッジ環境などに広がってきていると感じられる。 キーノートでも最近は Google 以外からの contribution が多いといったグラフがあったが、それも Kubernetes の用途が拡大していることを反映しているのではないかと思った。
次回以降の KubeCon は上海、シカゴ、パリの順で開催される。